
原神启动!(超级套娃)
进来后是一张照片和一个压缩包,对照片的red层分析后,得到压缩包的解密密码

解压后又喜提一个压缩包(虽说是docx文件,但是我们把后缀一改就得了)
改后缀得先等等,在word文档中,我们可以发现一共6个字符,但是上面只有5个字符,剩下的一个就是关键,是我们要解压的密码

是不是有点透明,考验你眼神的时候到了,得到的就是我们将docx后缀名改成zip后的压缩包的解密密码,然后又一次套娃我们得到了text.zip还是要密码啊,过程曲折,这里就直接上了
凑好密码后,我们就能得到flag了

emm~,虽说我不打原神,但还是谢谢
Easy
这道密码题比misc良心多了
进来后是两个txt附件,审计了代码后,我们可以看出这是一种典型的伪随机生成密码(PRNG)算法,类似于 RC4 加密算法的变种。
不废话了,直接上脚本吧
# 解密脚本
# 密钥
key = "hello world"
# 十六进制密文
cipher_text = bytes.fromhex("d8d2 963e 0d8a b853 3d2a 7fe2 96c5 2923 3924 6eba 0d29 2d57 5257 8359 322c 3a77 892d fa72 61b8 4f")
# 初始化 s 和 t 数组
s = list(range(256)) # s 数组初始化为 0-255
t = [ord(key[i % len(key)]) for i in range(256)] # t 数组使用密钥填充
# KSA - 密钥调度算法
j = 0
for i in range(256):
j = (j + s[i] + t[i]) % 256
s[i], s[j] = s[j], s[i]
# PRGA - 伪随机生成算法 (用于解密)
i = 0
j = 0
flag = bytearray(len(cipher_text))
for m in range(len(cipher_text)):
i = (i + 1) % 256
j = (j + s[i]) % 256
s[i], s[j] = s[j], s[i]
x = (s[i] + (s[j] % 256)) % 256
flag[m] = cipher_text[m] ^ s[x]
# 输出解密后的 flag
print("解密后的 flag:", flag.decode('utf-8', errors='ignore'))
解密后的 flag: WuCup{55a0a84f86a6ad40006f014619577ad3}Sign_misc
一串hex数字,直接解码就行
Sign_web
直接用蚁剑连接就能得到
if you know
先进行upx脱壳
在main里面可以看到我们要的东西
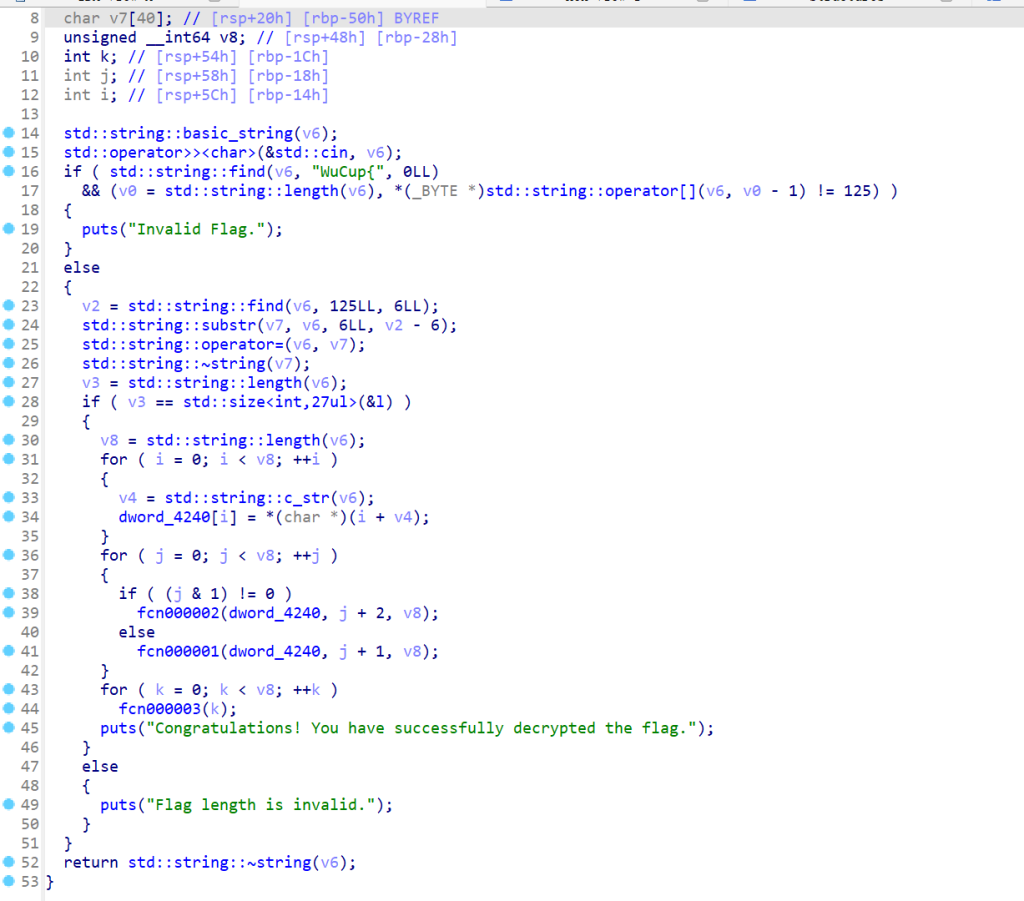
# 这里模拟你提供的三个函数
# 模拟 fcn000001
def fcn000001(a1, a2, a3):
for i in range(a3):
a1[i] = i + a2 + (i ^ a1[i])
return a3
# 模拟 fcn000002
def fcn000002(a1, a2, a3):
for i in range(a3 - 1, -1, -1):
a1[i] = i + a2 + (i ^ a1[i])
return a3
# 模拟 fcn000003
def fcn000003(a1, l, dword_4240):
for i in range(len(a1)):
if l[a1[i]] != dword_4240[a1[i]]:
print("Invalid flag please try again.")
exit(1)
return True
# 提供的 l 数组数据 (已转换为十进制)
l = [
0xF5, 0x200, 0x208, 0x1EF, 0x235, 0x274, 0x23A, 0x276, 0x2B7,
0x306, 0x2B2, 0x313, 0x2E2, 0x32F, 0x371, 0x440, 0x338, 0x3E9,
0x3E2, 0x3B6, 0x407, 0x43E, 0x3BA, 0x3F4, 0x415, 0x473, 0x4DA
]
# dword_4240 数组(假设它是加密后的目标 flag)
dword_4240 = [
0xF5, 0x200, 0x208, 0x1EF, 0x235, 0x274, 0x23A, 0x276, 0x2B7,
0x306, 0x2B2, 0x313, 0x2E2, 0x32F, 0x371, 0x440, 0x338, 0x3E9,
0x3E2, 0x3B6, 0x407, 0x43E, 0x3BA, 0x3F4, 0x415, 0x473, 0x4DA
]
# 反向解密过程
a1 = l.copy() # 假设这是初始加密数组
a2 = 0 # 假设为常量参数,根据实际情况调整
a3 = len(a1)
# 运行 fcn000001 和 fcn000002 来解密
fcn000001(a1, a2, a3)
fcn000002(a1, a2, a3)
# 现在通过 fcn000003 来验证 flag 是否正确
if fcn000003(a1, l, dword_4240):
# 输出解密后的 flag
flag = "".join([chr(x) for x in a1])
print("Congratulations! The flag is valid:", flag)
else:
print("Invalid flag.")
太极
这题着实有点脑洞
根据hint,我们只需要按照12345的顺序走,这时候就得考我拼音了
WuCup{tieny-lieig-sieau-bunig-jieay}
旋转木马
这有点难评,比赛期间没做出来,说真的,都不想复现
进行了53次base64加密,期间还涉及两个两个文件的取并集处理
直接上脚本吧
'''
import argparse
import base64
def decode_base64(input_file, output_file):
try:
# 打开输入文件并读取其内容
with open(input_file, 'rb') as f:
encoded_data = f.read()
# 解码Base64
decoded_data = base64.b64decode(encoded_data)
# 将解码后的数据写入输出文件
with open(output_file, 'wb') as f:
f.write(decoded_data)
print(f"解码成功,输出文件为: {output_file}")
except Exception as e:
print(f"发生错误: {e}")
def main():
# 创建解析器
parser = argparse.ArgumentParser(description='Base64 解码工具')
# 添加 -f 选项
parser.add_argument('-f', '--file', type=str, required=True, help='输入的Base64编码文件')
# 添加 -o 选项,指定输出文件名(可选,默认 "decoded_file")
parser.add_argument('-o', '--output', type=str, default='decoded_file', help='解码后的输出文件名')
# 解析命令行参数
args = parser.parse_args()
# 调用解码函数
decode_base64(args.file, args.output)
if __name__ == '__main__':
main()
'''
import argparse
import base64
def decode_base64_multiple_times(input_file, num_decodes):
try:
# 读取文件中的Base64编码数据
with open(input_file, 'rb') as f:
encoded_data = f.read()
# 执行多次解码
for i in range(num_decodes):
# 解码Base64
encoded_data = base64.b64decode(encoded_data)
print(f"第 {i + 1} 次解码后的数据:\n{encoded_data.decode(errors='ignore')}\n")
return encoded_data
except Exception as e:
print(f"发生错误: {e}")
def main():
# 创建解析器
parser = argparse.ArgumentParser(description='Base64 解码工具')
# 添加 -f 选项
parser.add_argument('-f', '--file', type=str, required=True, help='输入的Base64编码文件')
# 解析命令行参数
args = parser.parse_args()
# 设置解码次数
num_decodes = 52
# 执行多次解码
final_decoded_data = decode_base64_multiple_times(args.file, num_decodes)
# 输出最终解码结果
print(f"最终解码结果:\n{final_decoded_data.decode(errors='ignore')}")
if __name__ == '__main__':
main()
最上面注释的部分是进行一次解码,并生成文件,接下来我们要进行文件合并,windous上是copy吧,我在linux上用的是cat a b>c,然后使用下面没注释的代码进行解码
这里再优化下代码吧
import argparse
import base64
def decode_base64_multiple_times(input_file, num_decodes):
try:
# 读取文件中的Base64编码数据
with open(input_file, 'rb') as f:
encoded_data = f.read()
# 执行多次解码
for i in range(num_decodes):
# 解码Base64
encoded_data = base64.b64decode(encoded_data)
return encoded_data
except Exception as e:
print(f"发生错误: {e}")
def main():
# 创建解析器
parser = argparse.ArgumentParser(description='Base64 解码工具')
# 添加 -f 选项
parser.add_argument('-f', '--file', type=str, required=True, help='输入的Base64编码文件')
# 解析命令行参数
args = parser.parse_args()
# 设置解码次数
num_decodes = 52
# 执行多次解码
final_decoded_data = decode_base64_multiple_times(args.file, num_decodes)
# 输出最终解码结果
print(f"最终解码结果:\n{final_decoded_data.decode(errors='ignore')}")
if __name__ == '__main__':
main()
这串代码和上面的代码的区别是,它能直接输出结果,而最上面的代码是将每次代码被解码的结果都输出了
就这样吧
这场比赛拿了二等奖,但是是电子版,其他啥也没有滴,官方wp都没发给我们呢

这是奖状,wp我目前好像没找到,那就pass掉吧
Comments NOTHING