
曼彻斯特编码 (Manchester Encoding)
曼彻斯特编码是一种在数字通信和数据存储中广泛应用的线路编码技术。其核心特点是在每个数据位的中间时刻引入电平跳变,这个跳变既承载了时钟同步信号,也用于表示数据本身。由于其内置了同步机制,因此也被称为自同步码 (Self-Synchronizing Code) 或 相位编码 (Phase Encoding, PE)。
核心原理
曼彻斯特编码的基本思想是,每一个原始数据比特都被扩展为两个电平状态(或称为码元、chip)来表示。在每个原始比特的持续时间的中心点,信号电平必定会发生一次跳变。
这个在比特中点发生的跳变是曼彻斯特编码的关键,它为接收端提供了精确的时钟同步信息。数据的表示则依赖于这个跳变的方向,或者说,依赖于比特周期内前半部分和后半部分的电平高低组合。
编码规则的两种主要约定
对于标准的曼彻斯特编码,通常有两种广为流传的定义(它们在逻辑值与电平跳变方向的对应关系上正好相反):
-
IEEE 802.3 标准 (常用于以太网)
- 逻辑 ‘1’:表示为在比特周期中间从 低电平跳变到高电平 (LH)。
- 逻辑 ‘0’:表示为在比特周期中间从 高电平跳变到低电平 (HL)。
-
G.E. Thomas 提出的方式 (有时也被视为“经典”约定)
- 逻辑 ‘0’:表示为在比特周期中间从 低电平跳变到高电平 (LH)。
- 逻辑 ‘1’:表示为在比特周期中间从 高电平跳变到低电平 (HL)。
注意:G.E. Thomas 方式定义的标准曼彻斯特编码有时容易与“差分曼彻斯特编码”的概念混淆。关键在于,标准曼彻斯特编码(无论是 IEEE 802.3 还是 G.E. Thomas 约定)的核心是比特中间的跳变方向直接定义了数据值。而差分曼彻斯特编码的数据表示依赖于比特开始处是否有跳变。
关键特性
- 位中间跳变:无论传输的是逻辑 ‘0’ 还是 ‘1’,在每个比特周期的精确中间位置,信号电平都会发生一次转换。这是其最显著的物理特征。
- 同步信息:接收端可以检测这个位中间的跳变来精确地恢复时钟信号,从而与发送端保持同步。这有效解决了像不归零 (NRZ) 编码那样可能因连续的相同数据位而导致同步丢失的问题。
- 无直流分量 (No DC Component):由于每个比特周期内,高电平和低电平占据的时间通常是相等的(因为总有一次跳变),所以信号的平均直流分量趋近于零。这使得曼彻斯特编码的信号可以直接通过不允许有直流分量的传输介质,例如变压器耦合的线路。
- 错误检测能力:由于每个比特都必须有一次中点跳变,如果接收端在预期的中点没有检测到跳变,或者在不应该有跳变的地方(如比特边界处,对于非差分编码而言)检测到跳变,就可以指示可能发生了传输错误。
标准曼彻斯特编码示例
下面我们用表格清晰展示上述两种主要约定的标准曼彻斯特编码规则。我们约定高电平为 ‘1’,低电平为 ‘0’。
表 1: IEEE 802.3 曼彻斯特编码规则
| 原始数据 | 规则说明 (编码定义) | 比特周期 前半段电平 | 比特周期 后半段电平 | 形成的编码 (电平序列 1/0) | 比特中点 电平跳变方向 |
|---|---|---|---|---|---|
| 0 | 信号在比特中点由高跳变到低 | 高 (1) | 低 (0) | 10 | 高 → 低 |
| 1 | 信号在比特中点由低跳变到高 | 低 (0) | 高 (1) | 01 | 低 → 高 |
表 2: G.E. Thomas 曼彻斯特编码规则
| 原始数据 | 规则说明 (编码定义) | 比特周期 前半段电平 | 比特周期 后半段电平 | 形成的编码 (电平序列 1/0) | 比特中点 电平跳变方向 |
|---|---|---|---|---|---|
| 0 | 信号在比特中点由低跳变到高 | 低 (0) | 高 (1) | 01 | 低 → 高 |
| 1 | 信号在比特中点由高跳变到低 | 高 (1) | 低 (0) | 10 | 高 → 低 |
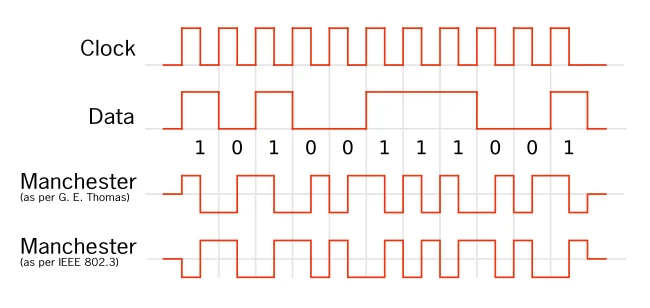
上图是根据两种规定的曼彻斯特编码方式
差分曼彻斯特编码 (Differential Manchester Encoding)
差分曼彻斯特编码是曼彻斯特编码的一种重要变种。它同样在每个比特周期的中间有一次电平跳变(主要用于时钟同步),但其表示数据的方式与标准曼彻斯特编码不同。
核心原理与编码规则
差分曼彻斯特编码通过比特周期的起始处是否存在电平跳变来表示数据:
- 逻辑 ‘0’:通过在比特周期的开始处引入一次电平跳变来表示(相对于前一个比特周期的结束电平而言)。
- 逻辑 ‘1’:通过在比特周期的开始处不发生电平跳变来表示(即当前比特的起始电平与前一个比特的结束电平相同)。
无论数据是 ‘0’ 还是 ‘1’,比特周期的中间仍然必须有一次电平跳变以维持时钟同步。这意味着差分曼彻斯特编码的每个比特单元的两个半周期电平也总是相反的。
关键特性
- 自同步性:与标准曼彻斯特编码一样,通过比特中点的固定跳变实现。
- 对信号极性不敏感(部分情况):由于数据是通过“变化”或“无变化”来表示的,而不是绝对的电平高低或跳变方向,因此在某些情况下,如果整个信号流的极性被意外反转,差分编码仍然可以被正确解码(但这取决于接收器的具体实现)。
- 需要初始参考:解码第一个比特时,需要知道数据流开始之前的线路电平状态,作为判断第一个比特开始处是否有跳变的参考。
- 无直流分量:与标准曼彻斯特编码类似。
差分曼彻斯特编码示例
下表展示了差分曼彻斯特编码的过程。注意,当前比特的编码依赖于前一个比特的结束电平。
| 原始数据 (D) | 前一比特 结束电平 (Prev_End) | 当前比特开始处 是否有跳变? | 当前比特 前半段电平 (S1) | 当前比特 后半段电平 (S2) (S2 必定与 S1 相反) | 形成的编码 (电平序列 S1S2) |
|---|---|---|---|---|---|
| (初始状态) | (假设为高 ‘1’) | - | - | - | - |
| 0 | 高 (‘1’) | 是 (S1≠Prev_End) | 低 (‘0’) | 高 (‘1’) | 01 |
| 1 | 高 (‘1’) | 否 (S1=Prev_End) | 高 (‘1’) | 低 (‘0’) | 10 |
| 0 | 低 (‘0’) | 是 (S1≠Prev_End) | 高 (‘1’) | 低 (‘0’) | 10 |
| 1 | 低 (‘0’) | 否 (S1=Prev_End) | 低 (‘0’) | 高 (‘1’) | 01 |
(上表示例中,S2 的选择是为了确保中点跳变,例如若 S1 为低,则 S2 为高,反之亦然。实际波形会自然形成这种中点跳变。)
曼彻斯特编码的解码过程
无论是标准曼彻斯特编码还是差分曼彻斯特编码,其解码过程都依赖于对信号中电平跳变的精确检测。
1. 时钟恢复与同步 (Clock Recovery and Synchronization)
- 寻找跳变:解码器首先持续检测输入信号中的电平跳变。对于这两种曼彻斯特编码,每个比特周期的中间都保证有一次跳变。
- 同步时钟:利用这些周期性的中点跳变,接收端可以调整其内部时钟,使其与发送数据的速率和相位同步。硬件实现中常使用锁相环 (PLL)。
- 确定比特边界:一旦时钟同步,接收端就能准确地划分出每个曼彻斯特编码符号(代表一个原始数据位)的起始和结束时刻,以及关键的比特周期中点。
2. 识别比特内的电平模式/跳变特征
对于每一个已确定边界的编码符号:
- 标准曼彻斯特解码:
- 方法一 (检测中点跳变方向):在比特周期的中间时刻,判断电平是从高跳到低 (H→L),还是从低跳到高 (L→H)。
- 方法二 (采样前后半段电平):分别采样比特周期前半段和后半段的电平,比较两者以确定是 “高-低”(HL) 模式还是 “低-高”(LH) 模式。
- 差分曼彻斯特解码:
- 获取当前比特周期的第一个半周期电平 (S1)。
- 获取前一个比特周期的第二个半周期电平 (即前一比特的结束电平)。
- 比较 S1 与前一比特的结束电平,判断当前比特开始时是否发生了跳变。
- 同时,必须验证当前比特的 S1 和 S2 是否相反,以确认比特内中点跳变的存在。如果 S1 和 S2 相同,则这是一个无效的差分曼彻斯特编码符号。
3. 应用编码规则进行解码
根据已知的编码标准(IEEE 802.3, G.E. Thomas, 或差分曼彻斯特)和上一步识别出的特征,将每个编码符号转换回原始的 ‘0’ 或 ‘1’。
- IEEE 802.3:
- 高 → 低 (HL /
10) 解码为 ‘0’。 - 低 → 高 (LH /
01) 解码为 ‘1’。
- 高 → 低 (HL /
- G.E. Thomas:
- 低 → 高 (LH /
01) 解码为 ‘0’。 - 高 → 低 (HL /
10) 解码为 ‘1’。
- 低 → 高 (LH /
- 差分曼彻斯特:
- 比特开始处有电平跳变,解码为 ‘0’。
- 比特开始处无电平跳变,解码为 ‘1’。
- (解码第一个比特时,需要知道数据流开始前的信号电平作为初始参考。)
4. 处理数据流
对接收到的整个曼彻斯特编码信号流,逐个编码符号重复上述同步、识别和解码步骤,最终将解码出的所有原始数据位按顺序排列,恢复出原始信息。
Summary
::: tip 这里给没有理解清楚的小白开个小灶,如果理解深刻的话,可以直接翻阅我下面写的 python 脚本以及小福利哈 ::: 相信上面的内容还是对小白不够友好,我这里做个总结,把过程再剖析下,希望大家能理解清楚
电脑是不直接认识字母’a’的,它只认识’0’,’1’,所以我们需要先把’a’变成标准的二进制暗号
在 ASCII 表中,字母 a 的十进制为 97,转换成 8 位二进制数后,就是01100001
这里的三种编码方式,我会选择一个很通俗易懂的例子:手电筒规则
IEEE 802.3 编码
想象一下,我们现在要用手电筒发送一串 01100001 给朋友,然后我们的手电筒只有两种状态:
- 亮(高电平,用 1 代表)
- 低(低电平,用 0 代表)
然后 IEEE 802.3 曼彻斯特编码的规则是:
- 要发送原始数据 0 时,我们需要让手电筒先亮一段时间,然后在发送这个 0 的时间段的正中间,立刻把手电筒变成灭,所以,0 的信号模式是“亮-灭”(即 10)
- 要发送原始数据 1 时,我们需要让手电筒先灭一段时间,然后在发送这个 1 的时间段的正中间,立刻把手电筒变成亮,所以,1 的信号模式是“灭-亮”(即 01)
接下来看那个字母 a,它的二进制编码是01100001
过程如下:
- 发送第一个比特
0:- 规则:
0→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则:
- 发送第二个比特
1:- 规则:
1→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则:
- 发送第三个比特
1:- 规则:
1→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则:
- 发送第四个比特
0:- 规则:
0→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则:
- 发送第五个比特
0:- 规则:
0→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则:
- 发送第六个比特
0:- 规则:
0→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则:
- 发送第七个比特
0:- 规则:
0→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则:
- 发送第八个比特
1:- 规则:
1→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则:
接下来将上面编码后的电平记录出来 10 01 01 10 10 10 10 01
感觉还算简单吧
G.E.Thomas 曼彻斯特编码
同样,我们使用字母 a 进行研究
G.E.Thomas 曼彻斯特编码的手电筒规则如下
- 要发送原始数据
0时:我们需要让手电筒先 灭 一小段时间,然后在发送这个0的时间段的 正中间,立刻把手电筒变成 亮。所以,0的信号模式是 “灭-亮”(即01)。 - 要发送原始数据
1时:我们需要让手电筒先 亮 一小段时间,然后在发送这个1的时间段的 正中间,立刻把手电筒变成 灭。所以,1的信号模式是 “亮-灭”(即10)。
这样的话,我们发送完整的数据的过程是
- 发送第一个比特
0:- 规则 (G.E. Thomas):
0→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则 (G.E. Thomas):
- 发送第二个比特
1:- 规则 (G.E. Thomas):
1→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则 (G.E. Thomas):
- 发送第三个比特
1:- 规则 (G.E. Thomas):
1→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则 (G.E. Thomas):
- 发送第四个比特
0:- 规则 (G.E. Thomas):
0→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则 (G.E. Thomas):
- 发送第五个比特
0:- 规则 (G.E. Thomas):
0→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则 (G.E. Thomas):
- 发送第六个比特
0:- 规则 (G.E. Thomas):
0→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则 (G.E. Thomas):
- 发送第七个比特
0:- 规则 (G.E. Thomas):
0→ “灭-亮” (01) - 手电筒动作:先灭,后亮。
- 编码后的电平:
01
- 规则 (G.E. Thomas):
- 发送第八个比特
1:- 规则 (G.E. Thomas):
1→ “亮-灭” (10) - 手电筒动作:先亮,后灭。
- 编码后的电平:
10
- 规则 (G.E. Thomas):
总结上面的所有电平信号:0110100101010110
小 Summary
这里给出我的理解,IEEE 802.3 编码结构是时钟+数据,也就是说,每两个数字中,一直是状态量+数据值,然后 G.E.Thomas 就不一样了,或者说恰恰相反,它的结构就是先数据值再状态量
差分曼彻斯特编码
这个类型就和前两个差距稍微明显了一点点
差分曼彻斯特编码的规则更加关注“变化”本身:
- 比特中间的跳变依然存在:和标准曼彻斯特编码一样,在每个原始比特的持续时间的正中间,手电筒的状态(亮/灭)必须反转一次。这是为了保持时钟同步。
- 数据的表示看比特开始时:
- 要发送原始数据
0时:在开始发送这个 ‘0’ 的那一刻,手电筒的状态必须与上一个比特结束时的状态相反(即发生一次电平跳变)。 - 要发送原始数据
1时:在开始发送这个 ‘1’ 的那一刻,手电筒的状态必须与上一个比特结束时的状态相同(即不发生电平跳变)。
- 要发送原始数据
关键点:差分编码需要知道“上一个比特结束时的状态”是什么。那么对于第一个要发送的比特,它“上一个比特”是什么呢?我们需要一个初始状态的约定。
这种编码关注的点其实是跳变,如果数据是 0 的话,我们就必须在最开始跳变一次,如果是 1 的话,我们就不能在最开始跳变
先看看发送数据的过程(假设初始手电筒是亮的,也就是说状态量为 1)
- 发送第一个比特
0:- 规则:发送 ‘0’ 时,比特开始处要有跳变。
- 当前手电筒是 亮 (‘1’)。为了有跳变,这个比特开始时手电筒要变成 灭 (‘0’) (这是比特的第一半状态)。
- 比特中间必须再次跳变:所以后半段手电筒从 灭(‘0’) 变成 亮 (‘1’)。
- 编码后的电平:
01。 - 更新状态:这个比特结束时,手电筒是 亮 (‘1’)。
- 发送第二个比特
1:- 规则:发送 ‘1’ 时,比特开始处无跳变。
- 上一个比特结束时手电筒是 亮 (‘1’)。为了无跳变,这个比特开始时手电筒保持 亮 (‘1’) (这是比特的第一半状态)。
- 比特中间必须再次跳变:所以后半段手电筒从 亮(‘1’) 变成 灭 (‘0’)。
- 编码后的电平:
10。 - 更新状态:这个比特结束时,手电筒是 灭 (‘0’)。
- 发送第三个比特
1:- 规则:发送 ‘1’ 时,比特开始处无跳变。
- 上一个比特结束时手电筒是 灭 (‘0’)。为了无跳变,这个比特开始时手电筒保持 灭 (‘0’)。
- 比特中间跳变:后半段变成 亮 (‘1’)。
- 编码后的电平:
01。 - 更新状态:这个比特结束时,手电筒是 亮 (‘1’)。
- 发送第四个比特
0:- 规则:发送 ‘0’ 时,比特开始处要有跳变。
- 上一个比特结束时手电筒是 亮 (‘1’)。为了有跳变,这个比特开始时变成 灭 (‘0’)。
- 比特中间跳变:后半段变成 亮 (‘1’)。
- 编码后的电平:
01。 - 更新状态:这个比特结束时,手电筒是 亮 (‘1’)。
- 发送第五个比特
0: (同上,前一个结束为亮’1’)- 编码后的电平:
01。 - 更新状态:结束时为 亮 (‘1’)。
- 编码后的电平:
- 发送第六个比特
0: (同上,前一个结束为亮’1’)- 编码后的电平:
01。 - 更新状态:结束时为 亮 (‘1’)。
- 编码后的电平:
- 发送第七个比特
0: (同上,前一个结束为亮’1’)- 编码后的电平:
01。 - 更新状态:结束时为 亮 (‘1’)。
- 编码后的电平:
- 发送第八个比特
1:- 规则:发送 ‘1’ 时,比特开始处无跳变。
- 上一个比特结束时手电筒是 亮 (‘1’)。为了无跳变,这个比特开始时保持 亮 (‘1’)。
- 比特中间跳变:后半段变成 灭 (‘0’)。
- 编码后的电平:
10。 - 更新状态:这个比特结束时,手电筒是 灭 (‘0’)。
总结下所有的电平信号,得到了 0110010101010110
希望上面的 Summary 能帮助到大家
Python 脚本 (用于编码)
以下是一个 python 脚本,它可以读取任意路径的文件,任意格式,然后可以自定义三种曼彻斯特编码模式,以及选择是否进行逆序处理
还有 ASCII 预览呢
import os
def encode_manchester_ieee802_3(binary_data_string):
"""使用 IEEE 802.3 标准进行曼彻斯特编码"""
encoded_bits = []
for bit in binary_data_string:
if bit == '0':
encoded_bits.append("10") # 0 -> HL
elif bit == '1':
encoded_bits.append("01") # 1 -> LH
else:
print(f"警告 (IEEE 802.3):在二进制数据串中遇到无效比特 '{bit}',已跳过。")
continue
return "".join(encoded_bits)
def encode_manchester_ge_thomas(binary_data_string):
"""使用 G.E. Thomas 标准进行曼彻斯特编码"""
encoded_bits = []
for bit in binary_data_string:
if bit == '0':
encoded_bits.append("01") # 0 -> LH
elif bit == '1':
encoded_bits.append("10") # 1 -> HL
else:
print(f"警告 (G.E. Thomas):在二进制数据串中遇到无效比特 '{bit}',已跳过。")
continue
return "".join(encoded_bits)
def encode_differential_manchester(binary_data_string, initial_level_char):
"""使用差分曼彻斯特标准进行编码"""
if initial_level_char not in ('0', '1'):
print("错误 (差分曼彻斯特):无效的初始电平状态。必须是 '0' 或 '1'。")
return None
encoded_bits = []
current_signal_end_level = initial_level_char
for bit_to_encode in binary_data_string:
first_half_level = ''
second_half_level = ''
if bit_to_encode == '1':
first_half_level = current_signal_end_level
elif bit_to_encode == '0':
first_half_level = '1' if current_signal_end_level == '0' else '0'
else:
print(f"警告 (差分曼彻斯特):在二进制数据串中遇到无效比特 '{bit_to_encode}',已跳过。")
continue
second_half_level = '1' if first_half_level == '0' else '0'
encoded_bits.append(first_half_level + second_half_level)
current_signal_end_level = second_half_level
return "".join(encoded_bits)
def main():
print("曼彻斯特编码脚本")
print("=" * 30)
input_file_path = input("请输入包含原始数据的文件路径 (例如 data.txt 或 data.zip): ")
try:
with open(input_file_path, 'rb') as file:
original_byte_content = file.read() # 读取为字节序列 (bytes object)
if not original_byte_content:
print("错误:输入文件为空。")
return
except FileNotFoundError:
print(f"错误:文件 '{input_file_path}' 未找到。")
return
except Exception as e:
print(f"读取文件 '{input_file_path}' 时发生错误: {e}")
return
binary_to_encode_original = "".join(format(byte, '08b') for byte in original_byte_content)
if not binary_to_encode_original:
print("错误:未能将文件内容转换为二进制数据。")
return
print(f"\n已读取文件: {input_file_path}")
print(f"文件大小: {len(original_byte_content)} 字节")
bytes_to_preview = min(len(original_byte_content), 32)
hex_preview_str = " ".join(f"{b:02X}" for b in original_byte_content[:bytes_to_preview])
print(f"原始文件数据的前 {bytes_to_preview} 字节 (十六进制): {hex_preview_str}{'...' if len(original_byte_content) > bytes_to_preview else ''}")
print(f"转换后的二进制数据串 (前80位): {binary_to_encode_original[:80]}{'...' if len(binary_to_encode_original) > 80 else ''}")
print(f"(二进制数据总长度: {len(binary_to_encode_original)} 比特)")
binary_to_encode_final = binary_to_encode_original
is_source_reversed = False
if binary_to_encode_original:
reverse_source_choice = input("\n是否需要在编码前将上述【原始二进制数据串】进行整体逆序? (y/n, 默认为 n): ").strip().lower()
if reverse_source_choice == 'y':
binary_to_encode_final = binary_to_encode_original[::-1]
is_source_reversed = True
print("提示:原始二进制数据已在编码前进行了逆序处理。")
print(f"逆序后的待编码二进制数据串 (前80位): {binary_to_encode_final[:80]}{'...' if len(binary_to_encode_final) > 80 else ''}")
print("\n请选择曼彻斯特编码标准:")
print("1: IEEE 802.3 (数据 '0'->'10', '1'->'01')")
print("2: G.E. Thomas (数据 '0'->'01', '1'->'10')")
print("3: 差分曼彻斯特 (数据 '0'->起始跳变, '1'->起始无跳变)")
choice = input("请输入选项 (1, 2 或 3): ").strip()
manchester_encoded_string = None
standard_name = ""
initial_level_for_diff = ''
if choice == '1':
standard_name = "IEEE_802.3"
manchester_encoded_string = encode_manchester_ieee802_3(binary_to_encode_final)
elif choice == '2':
standard_name = "GE_Thomas"
manchester_encoded_string = encode_manchester_ge_thomas(binary_to_encode_final)
elif choice == '3':
standard_name = "Differential_Manchester"
while True:
initial_level_for_diff = input("差分曼彻斯特编码需要一个初始电平。\n请输入在编码开始之前的信号电平 ('0' 代表低, '1' 代表高): ").strip()
if initial_level_for_diff in ('0', '1'):
break
else:
print("无效输入,请输入 '0' 或 '1'。")
manchester_encoded_string = encode_differential_manchester(binary_to_encode_final, initial_level_for_diff)
else:
print("错误:无效的选项。")
return
if manchester_encoded_string is None:
print("编码失败。")
return
print(f"\n--- 使用 {standard_name.replace('_', ' ')} 标准编码完成 ---")
if is_source_reversed:
print("(注意:是对逆序后的原始二进制数据进行的编码)")
if standard_name == "Differential_Manchester":
print(f"(编码时假定的初始电平为: '{initial_level_for_diff}')")
print(f"编码后的曼彻斯特序列 (前100个字符): {manchester_encoded_string[:100]}{'...' if len(manchester_encoded_string) > 100 else ''}")
print(f"(编码后总长度: {len(manchester_encoded_string)} 字符)")
input_filename_part = os.path.basename(input_file_path)
base_input_name, input_ext = os.path.splitext(input_filename_part)
if not input_ext:
input_ext = ".txt"
reversal_info_suffix = "_source_reversed" if is_source_reversed else ""
output_file_default = f"{base_input_name}_encoded_{standard_name}{reversal_info_suffix}{input_ext}"
output_file_path = input(f"\n请输入保存编码后数据的文件名 (默认为: {output_file_default}): ").strip()
if not output_file_path:
output_file_path = output_file_default
try:
with open(output_file_path, 'w') as outfile:
outfile.write(manchester_encoded_string)
print(f"编码后的数据已成功保存到: {output_file_path}")
except Exception as e:
print(f"错误:无法保存编码数据到文件 '{output_file_path}': {e}")
if __name__ == "__main__":
main()Python 脚本 (用于解码)
以下是一个 Python 脚本,它可以读取包含 ‘0’ 和 ‘1’ 字符(代表编码后的电平状态)的文件,并根据用户选择的曼彻斯特编码标准(包括差分曼彻斯特)进行解码,同时提供 ASCII 预览和逆序选项。
import os
def decode_manchester_ieee802_3(encoded_data_str):
"""
使用 IEEE 802.3 标准解码曼彻斯特编码字符串。
规则: '01' (低-高) -> '1', '10' (高-低) -> '0'.
"""
decoded_bits = []
errors = []
warnings = []
n = len(encoded_data_str)
for i in range(0, n - (n % 2), 2):
pair = encoded_data_str[i:i+2]
if pair == "01":
decoded_bits.append("1")
elif pair == "10":
decoded_bits.append("0")
else:
errors.append(f"错误 (IEEE 802.3):在位置 {i} 发现无效的曼彻斯特编码对 '{pair}' (应为 '01' 或 '10')。")
if n % 2 != 0:
warnings.append(f"警告:输入编码数据长度为奇数 ({n})。最后一个字符 '{encoded_data_str[-1]}' 已被忽略。")
return "".join(decoded_bits), errors, warnings
def decode_manchester_ge_thomas(encoded_data_str):
"""
使用 G.E. Thomas 标准解码曼彻斯特编码字符串。
规则: '01' (低-高) -> '0', '10' (高-低) -> '1'.
"""
decoded_bits = []
errors = []
warnings = []
n = len(encoded_data_str)
for i in range(0, n - (n % 2), 2):
pair = encoded_data_str[i:i+2]
if pair == "01":
decoded_bits.append("0")
elif pair == "10":
decoded_bits.append("1")
else:
errors.append(f"错误 (G.E. Thomas):在位置 {i} 处发现无效的曼彻斯特编码对 '{pair}' (应为 '01' 或 '10')。")
if n % 2 != 0:
warnings.append(f"警告:输入编码数据长度为奇数 ({n})。最后一个字符 '{encoded_data_str[-1]}' 已被忽略。")
return "".join(decoded_bits), errors, warnings
def decode_differential_manchester(encoded_data_str, initial_prev_level_char):
"""
使用差分曼彻斯特标准解码编码字符串。
规则: 比特开始处有跳变 -> '0', 无跳变 -> '1'.
每个比特内部必须有中点跳变 (即两个半周期电平不同).
"""
decoded_bits = []
errors = []
warnings = []
n = len(encoded_data_str)
if initial_prev_level_char not in ('0', '1'):
errors.append("严重错误 (差分曼彻斯特):无效的初始前一电平状态。必须是 '0' 或 '1'。")
return "", errors, warnings
previous_level_second_half = initial_prev_level_char
for i in range(0, n - (n % 2), 2):
s1 = encoded_data_str[i]
s2 = encoded_data_str[i+1]
if s1 == s2:
errors.append(f"错误 (差分曼彻斯特):在位置 {i} 处发现无效符号 '{s1}{s2}',缺少比特内中点跳变。")
if s1 == previous_level_second_half:
decoded_bits.append("1")
else:
decoded_bits.append("0")
previous_level_second_half = s2
if n % 2 != 0:
warnings.append(f"警告:输入编码数据长度为奇数 ({n})。最后一个字符 '{encoded_data_str[-1]}' 已被忽略。")
return "".join(decoded_bits), errors, warnings
def binary_to_ascii_preview(binary_str, max_chars=50, bits_per_char=8):
"""
将二进制字符串的前缀转换为ASCII字符预览。
非标准可打印ASCII字符将用 '.' 代替。
"""
if not binary_str or len(binary_str) < bits_per_char:
return "(二进制数据不足以转换为ASCII)"
ascii_chars = []
num_full_chars_possible = len(binary_str) // bits_per_char
for i in range(min(num_full_chars_possible, max_chars)):
byte_str = binary_str[i*bits_per_char : (i+1)*bits_per_char]
try:
decimal_value = int(byte_str, 2)
if 32 <= decimal_value <= 126:
ascii_chars.append(chr(decimal_value))
else:
ascii_chars.append('.')
except ValueError:
ascii_chars.append('?')
return "".join(ascii_chars)
def binary_string_to_bytes(binary_str):
"""
将一个01组成的二进制字符串转换为bytes对象。
如果长度不是8的倍数,末尾不足一个字节的部分将被忽略,并收集警告。
"""
conversion_warnings = []
if len(binary_str) % 8 != 0:
conversion_warnings.append(
f"警告 (二进制转字节):解码后的二进制数据长度 ({len(binary_str)}) 不是8的倍数。"
"保存为原始二进制文件时,末尾不足一个字节的部分将被忽略。"
)
byte_array = bytearray()
for i in range(0, len(binary_str) - (len(binary_str) % 8), 8):
byte_segment = binary_str[i:i+8]
try:
byte_array.append(int(byte_segment, 2))
except ValueError:
print(f"严重错误:在二进制转字节过程中发现无效的8位块 '{byte_segment}'。")
return None, conversion_warnings
return bytes(byte_array), conversion_warnings
def main():
file_path = input("请输入包含曼彻斯特编码数据的文件路径: ")
try:
with open(file_path, 'r') as file:
raw_content = file.read()
signal_string_no_whitespace = "".join(raw_content.split())
valid_chars = []
invalid_char_messages = []
for char_idx, char_val in enumerate(signal_string_no_whitespace):
if char_val in ('0', '1'):
valid_chars.append(char_val)
else:
invalid_char_messages.append(f"警告:在原始数据中发现并忽略了无效字符 '{char_val}' (在清理空白后的位置 {char_idx})。")
manchester_encoded_string = "".join(valid_chars)
if invalid_char_messages:
print("\n--- 输入数据清理警告 ---")
for msg in invalid_char_messages:
print(msg)
if not manchester_encoded_string:
print("错误:文件内容为空或不包含有效的 '0' 或 '1' 字符以供解码。")
return
print(f"\n读取并清理后的待解码数据 (长度 {len(manchester_encoded_string)}): {manchester_encoded_string[:100]}{'...' if len(manchester_encoded_string) > 100 else ''}")
print("\n请选择曼彻斯特解码标准:")
print("1: IEEE 802.3 (电平序列 '01' -> 数据 '1', '10' -> 数据 '0')")
print("2: G.E. Thomas (电平序列 '01' -> 数据 '0', '10' -> 数据 '1')")
print("3: 差分曼彻斯特 (比特初有跳变为'0', 无则为'1'; 比特中点必有跳变)")
standard_choice = input("请输入选项 (1, 2 或 3): ").strip()
decoded_data_initial = ""
errors = []
warnings_from_decode = []
standard_name = ""
initial_level_for_diff = ''
if standard_choice == '1':
standard_name = "IEEE 802.3"
decoded_data_initial, errors, warnings_from_decode = decode_manchester_ieee802_3(manchester_encoded_string)
elif standard_choice == '2':
standard_name = "G.E. Thomas"
decoded_data_initial, errors, warnings_from_decode = decode_manchester_ge_thomas(manchester_encoded_string)
elif standard_choice == '3':
standard_name = "差分曼彻斯特"
while True:
initial_level_for_diff = input("请输入在数据流开始之前的信号电平 ('0' 表示低电平, '1' 表示高电平): ").strip()
if initial_level_for_diff in ('0', '1'):
break
else:
print("无效的输入,请输入 '0' 或 '1'。")
decoded_data_initial, errors, warnings_from_decode = decode_differential_manchester(manchester_encoded_string, initial_level_for_diff)
else:
print("错误:无效的解码标准选项。程序将退出。")
return
print(f"\n--- 使用 {standard_name} 标准进行解码 ---")
if standard_name == "差分曼彻斯特":
print(f"(假设数据流开始前的电平为: '{initial_level_for_diff}')")
if warnings_from_decode:
print("\n--- 解码过程警告 ---")
for warning_msg in warnings_from_decode:
print(warning_msg)
if errors:
print("\n--- 解码过程错误 ---")
for error_msg in errors:
print(error_msg)
print(f"共发现 {len(errors)} 个错误。")
data_to_process = decoded_data_initial
is_reversed_flag = False
if not errors and data_to_process:
print_initial_binary_choice = input(
f"\n解码后的原始二进制数据长度为 {len(data_to_process)} 比特。"
"是否在控制台完整打印? (y/n, 默认为 n): "
).strip().lower()
if print_initial_binary_choice == 'y':
print(f"\n--- 解码后的原始数据 ({standard_name} 标准) ---")
chunk_size = 80
for i in range(0, len(data_to_process), chunk_size):
print(data_to_process[i:i+chunk_size])
else:
print(f"提示:已跳过在控制台打印 {len(data_to_process)} 比特的解码后原始二进制数据。")
print("\n--- ASCII预览 (前约50字符, 基于8位/字符, 基于上述解码数据) ---")
ascii_preview_str = binary_to_ascii_preview(data_to_process, max_chars=50, bits_per_char=8)
print(f"ASCII预览: {ascii_preview_str}")
print("(提示: 非标准可打印字符显示为'.'。此预览可帮助判断解码模式是否正确。)")
reverse_choice = input("\n是否需要将解码后的二进制数据串进行整体逆序? (y/n, 默认为 n): ").strip().lower()
if reverse_choice == 'y':
data_to_process = data_to_process[::-1]
is_reversed_flag = True
print("提示:数据已进行逆序处理。")
print_reversed_binary_choice = input(
f"逆序后的二进制数据长度为 {len(data_to_process)} 比特。"
"是否在控制台完整打印? (y/n, 默认为 n): "
).strip().lower()
if print_reversed_binary_choice == 'y':
print(f"\n--- 逆序后的解码数据 ({standard_name} 标准) ---")
chunk_size = 80
for i in range(0, len(data_to_process), chunk_size):
print(data_to_process[i:i+chunk_size])
else:
print(f"提示:已跳过在控制台打印 {len(data_to_process)} 比特的逆序后二进制数据。")
print("\n--- 逆序后数据的ASCII预览 (前约50字符, 基于8位/字符) ---")
reversed_ascii_preview_str = binary_to_ascii_preview(data_to_process, max_chars=50, bits_per_char=8)
print(f"逆序后ASCII预览: {reversed_ascii_preview_str}")
elif not data_to_process and not errors:
print("\n未能解码出有效数据(可能是因为输入数据过短或在错误清理/过滤后已为空)。")
if not errors and data_to_process:
print("-" * 30)
input_filename_part = os.path.basename(file_path)
base_input_name, input_ext_original = os.path.splitext(input_filename_part)
safe_standard_name = standard_name.replace(" ", "_").replace(".", "").replace("(", "").replace(")", "")
reversal_suffix = "_reversed" if is_reversed_flag else ""
print("\n您希望如何保存解码后的数据?")
print(" 1: 作为文本文件 (包含01二进制字符串)")
print(" 2: 作为原始二进制文件 (例如,用于恢复原始的 .zip, .jpg, .exe 等文件)")
save_format_choice = input("请输入选项 (1 或 2, 默认为 1): ").strip()
output_ext = ".txt"
save_as_binary_flag = False
if save_format_choice == '2':
output_ext = input_ext_original if input_ext_original and input_ext_original != "." else ".bin"
save_as_binary_flag = True
output_file_path_default = f"{base_input_name}_decoded_{safe_standard_name}{reversal_suffix}{output_ext}"
save_prompt_message = f"处理结果 ({standard_name} 标准{' - 数据已按需处理(如逆序)' if is_reversed_flag else ''})。\n请输入保存数据的文件名 (默认为: {output_file_path_default}): "
output_file_path = input(save_prompt_message)
if not output_file_path:
output_file_path = output_file_path_default
try:
if save_as_binary_flag:
bytes_to_save, conv_warnings = binary_string_to_bytes(data_to_process)
if conv_warnings:
print("\n--- 二进制转换警告 ---")
for warn_msg in conv_warnings:
print(warn_msg)
if bytes_to_save is not None:
with open(output_file_path, 'wb') as outfile:
outfile.write(bytes_to_save)
print(f"数据已作为原始二进制文件成功保存到: {output_file_path}")
else:
print("错误:无法将01字符串转换为字节数据,文件未以二进制格式保存。")
else:
with open(output_file_path, 'w') as outfile:
outfile.write(data_to_process)
print(f"数据已作为01二进制字符串文本文件成功保存到: {output_file_path}")
except Exception as e:
print(f"错误:无法保存数据到文件 '{output_file_path}': {e}")
elif errors:
print("\n由于解码过程中检测到错误,数据将不会自动保存到文件。")
elif not data_to_process and not errors:
print("\n没有有效的解码数据可以保存。")
except FileNotFoundError:
print(f"错误:文件 '{file_path}' 未找到。")
except Exception as e:
print(f"处理文件时发生意外错误: {e}")
if __name__ == "__main__":
main()小福利(网鼎杯-朱雀组-Misc1)
特别安利平台 CTF+
这是题目链接https://www.ctfplus.cn/problem-detail/1863418368669782016/description
下载附件,发现只有 01 的字符串,最开始我以为是二进制转 ASCII 呢,可惜不是
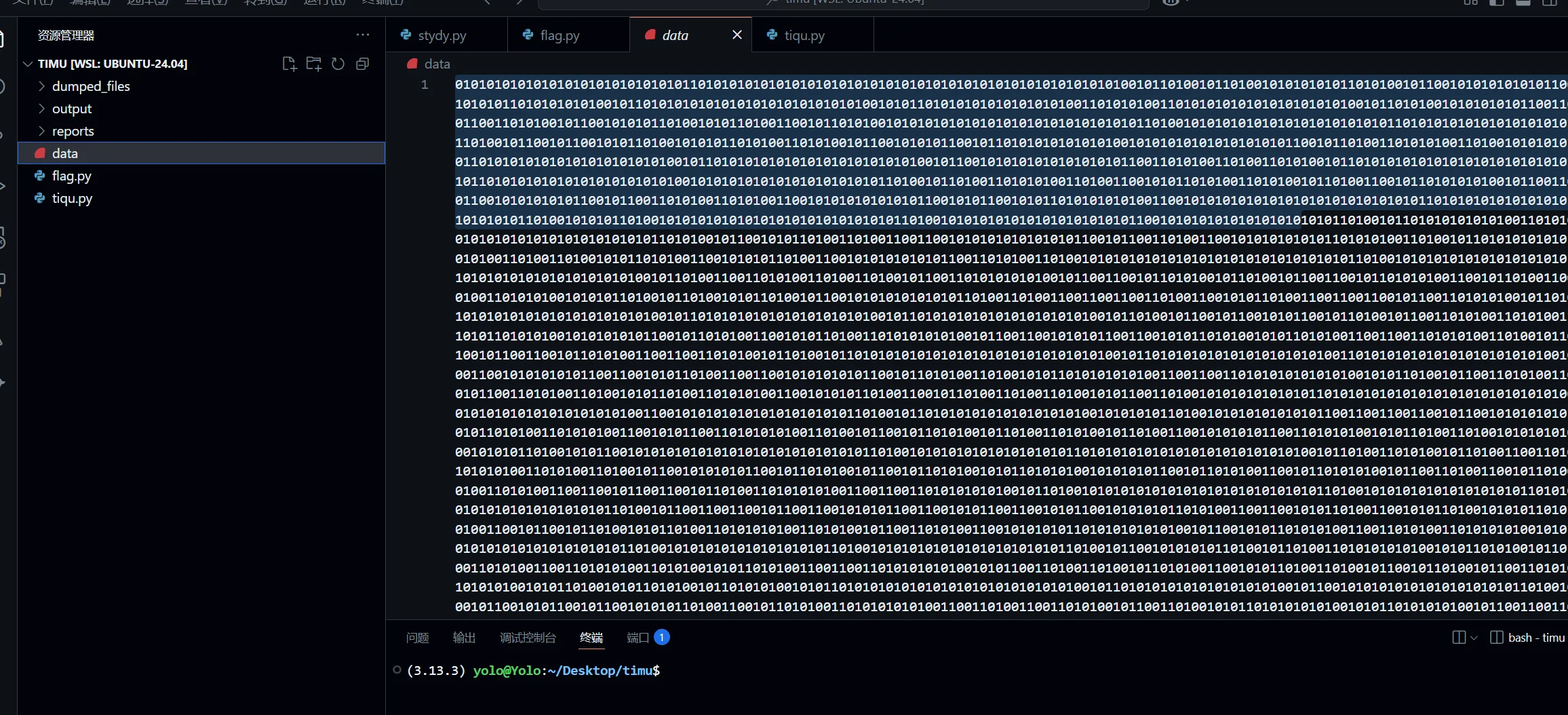
后来研究了下,发现是曼彻斯特编码:tired_face:
鉴于曼彻斯特就那么几种编码而已,我就索性一个一个尝试了呗,就三个,尝试过前两个,都没看出什么东西,

但是在差分这里出现了特别特殊的东西,PK
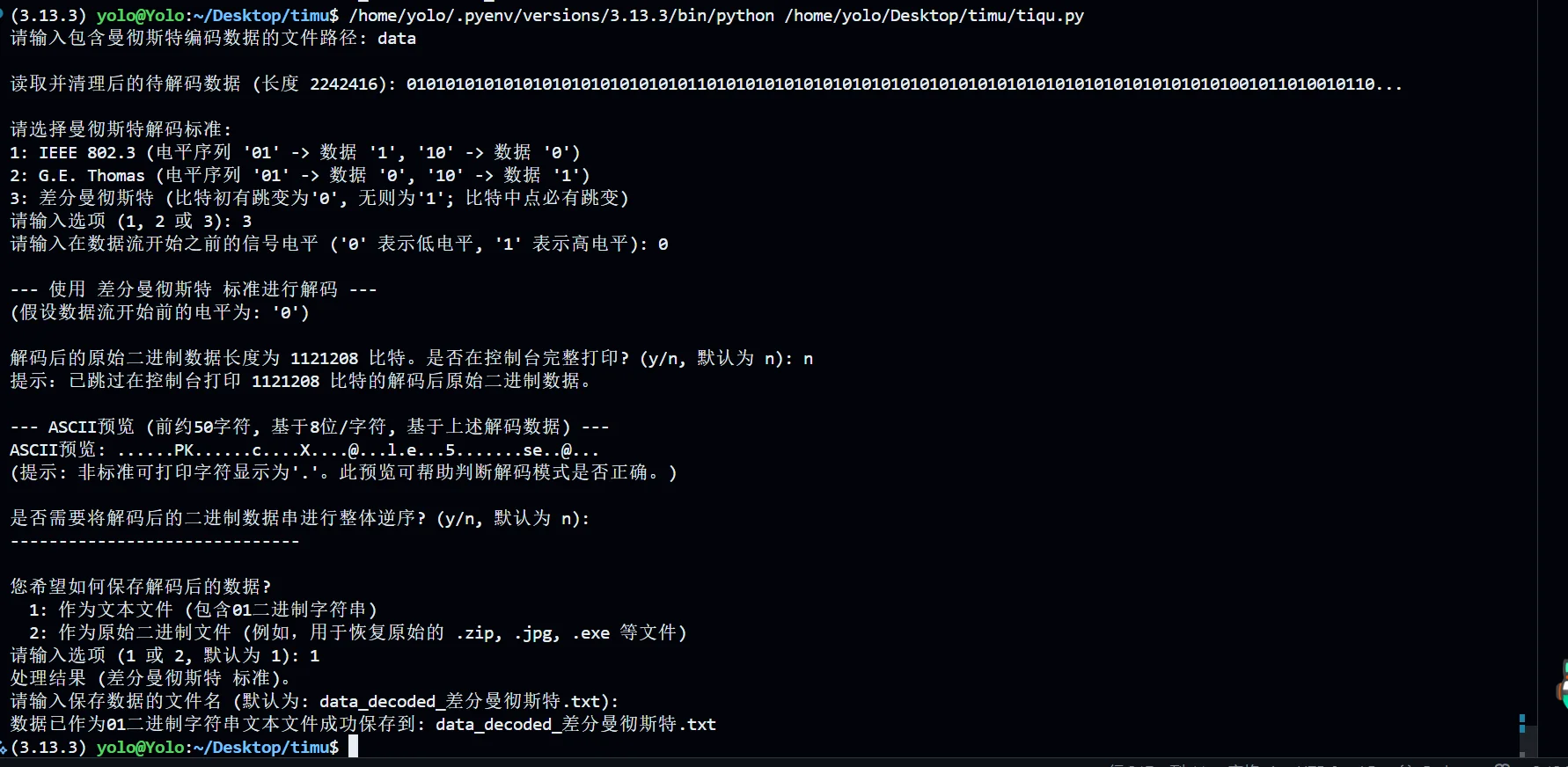
就先提取下来好了,我现在检查下这个压缩包
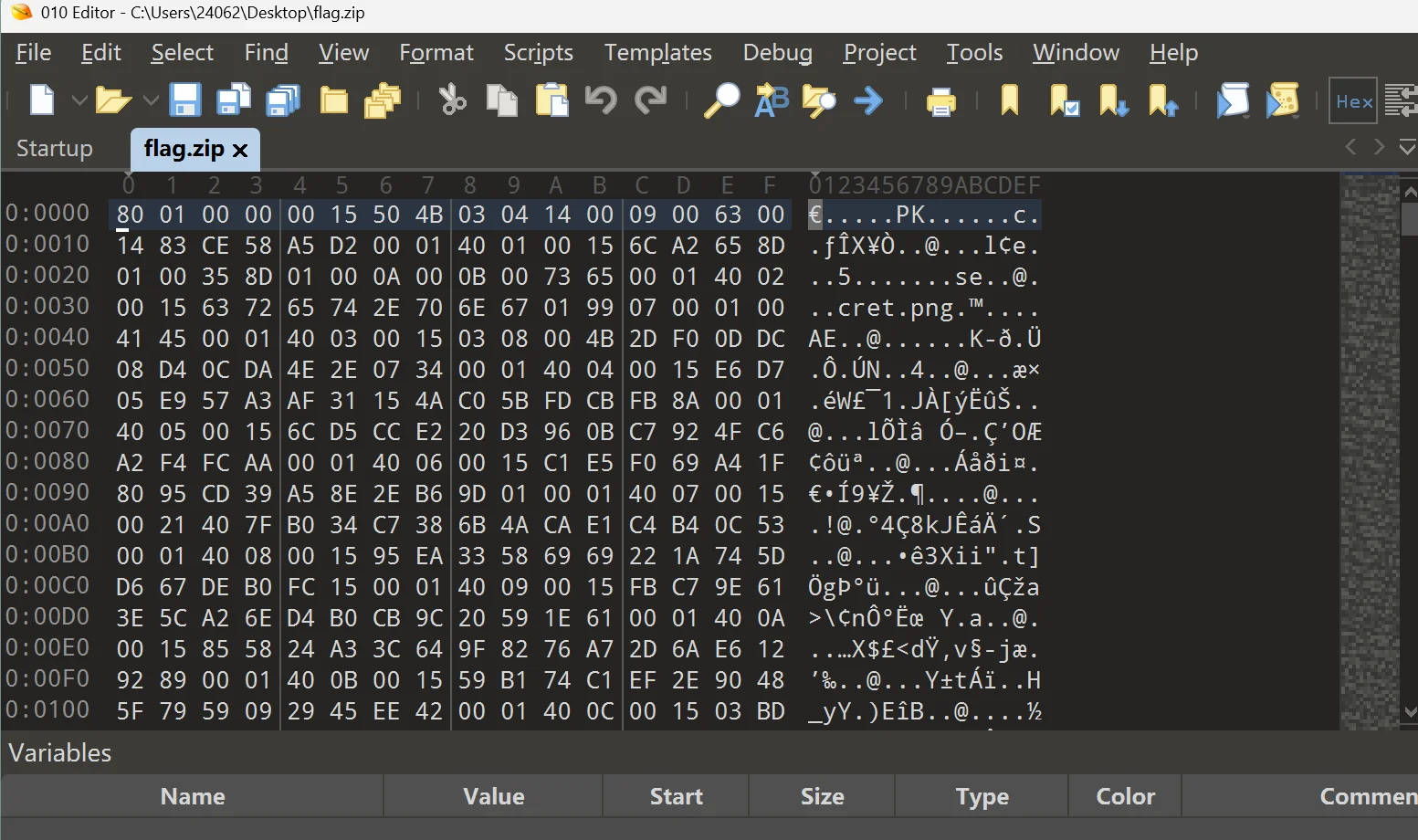
有些地方有点点小问题,我看着改改
如果没有记住 zip 的详细结构的话,这里有个小技巧,就是随便压缩个文件,一一比对
来看看文件结尾
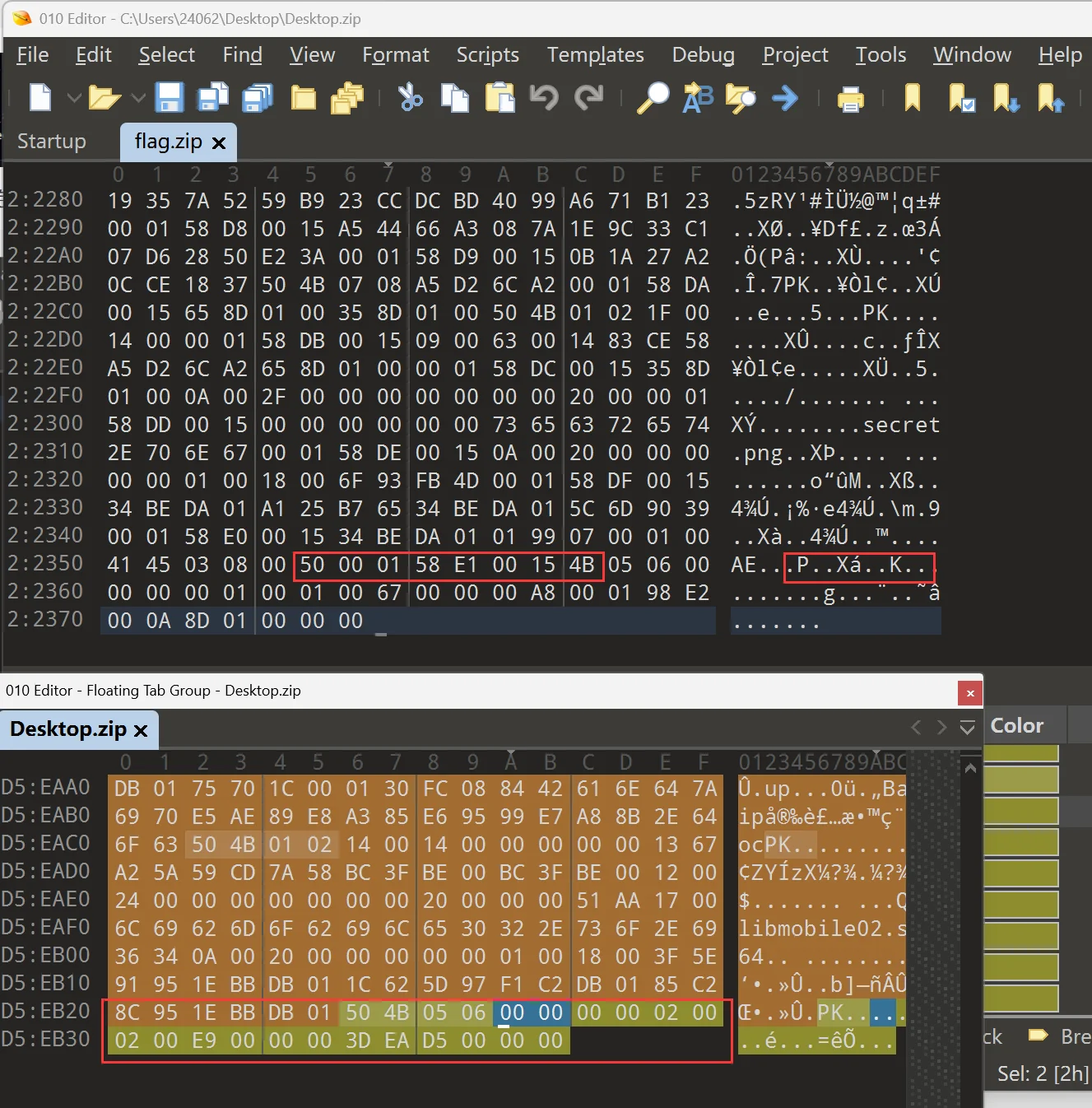
但是呢,我越改越感觉不对,一个是工作量太大了吧,另一个是不太好盯这里的差异,不过我发现了一点,结合最开头的未知 6 字节,加上这里插入的 6 字节,出题人这里插入的数据还挺规律的,那就先查看下整个压缩包的 16 进制的特殊地方吧,这里我选择一行按照 44 个字节输出,理由是 6+16+6+16,这里的 16 是因为我发现最前面的 zip 压缩包的魔数是 16 字节没有问题的,maybe 这样可以将规律找出来
import binascii
def zip_to_hex_formatted(zip_file_path, output_txt_path, bytes_per_line=44):
"""
将 ZIP 文件转换为十六进制格式并保存到文本文件。
参数:
zip_file_path (str): 输入的 ZIP 文件路径。
output_txt_path (str): 输出的 TXT 文件路径。
bytes_per_line (int): 每行输出的字节数。
"""
try:
with open(zip_file_path, 'rb') as zip_file, open(output_txt_path, 'w') as txt_file:
while True:
chunk = zip_file.read(bytes_per_line)
if not chunk:
break
hex_representation = binascii.hexlify(chunk).decode('ascii')
formatted_line = ''
for i in range(0, len(hex_representation), 2):
formatted_line += hex_representation[i:i+2] + ' '
txt_file.write(formatted_line.strip() + '\n')
print(f"成功将 '{zip_file_path}' 的十六进制内容输出到 '{output_txt_path}'")
print(f"每行包含 {bytes_per_line} 个字节。")
except FileNotFoundError:
print(f"错误:输入文件 '{zip_file_path}' 未找到。")
except Exception as e:
print(f"处理文件时发生错误:{e}")
if __name__ == "__main__":
zip_file = input("请输入ZIP文件的路径: ")
txt_file = input("请输入要保存的TXT文件的路径 (例如 output.txt): ")
bytes_on_each_line = 44
zip_to_hex_formatted(zip_file, txt_file, bytes_on_each_line)运行完脚本后,就得到了很显然的规律
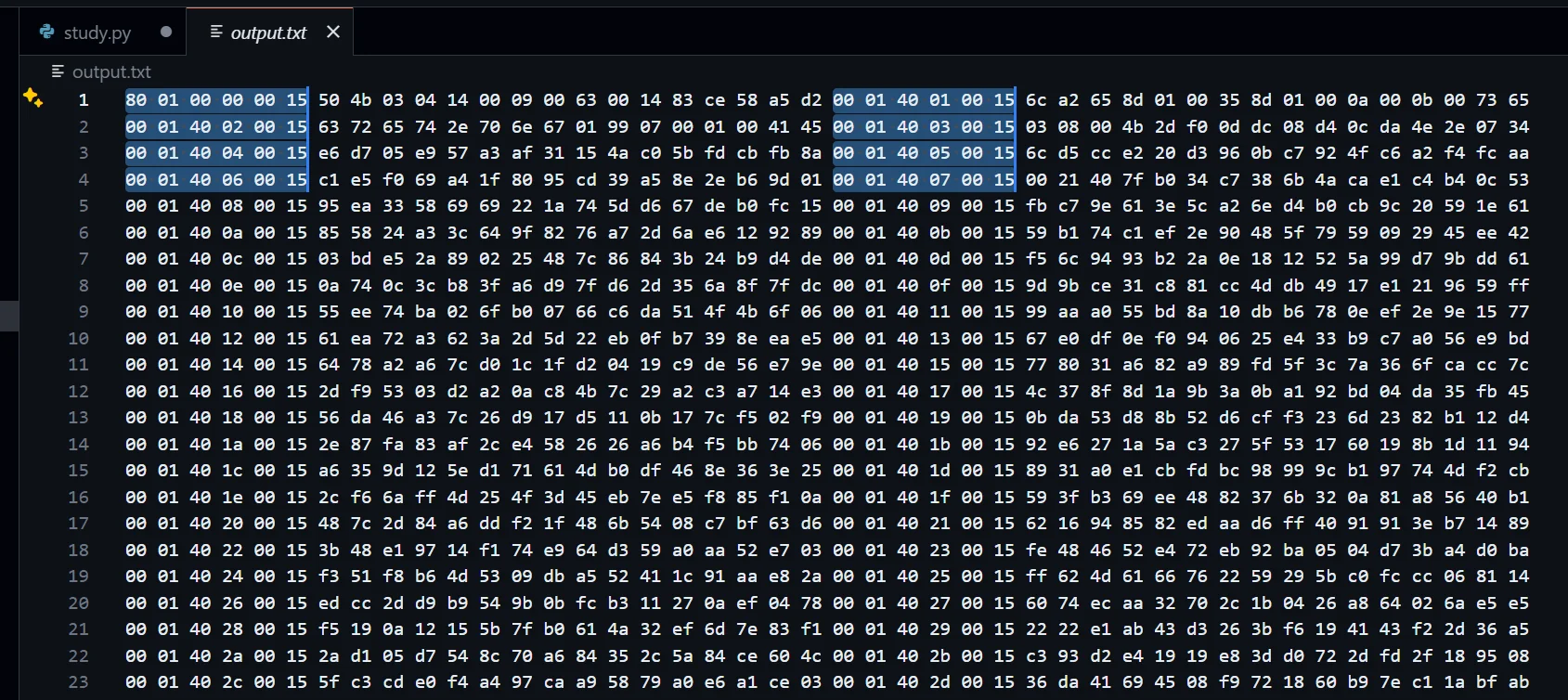
但是这里并不允许我使用查找功能替换掉那些多余数据,那就继续 6+16+6+16 咯
def process_binary_file_by_position(input_binary_path, output_binary_path):
"""
直接读取二进制文件,按照 "跳过6字节,保留16字节" 的模式处理字节流,
并将保留的字节数据写入新的二进制文件。
参数:
input_binary_path (str): 输入的原始二进制文件路径 (例如 .zip 文件)。
output_binary_path (str): 输出的处理后的二进制文件路径。
"""
bytes_to_skip = 6
bytes_to_keep = 16
kept_byte_chunks = []
try:
with open(input_binary_path, 'rb') as infile:
input_binary_data = infile.read()
if not input_binary_data:
print(f"警告: 输入文件 '{input_binary_path}' 为空或无法读取。")
return
current_pos = 0
data_length = len(input_binary_data)
while current_pos < data_length:
next_data_start_pos = current_pos + bytes_to_skip
if next_data_start_pos >= data_length:
break
current_pos = next_data_start_pos
data_chunk_end_pos = min(current_pos + bytes_to_keep, data_length)
data_chunk = input_binary_data[current_pos : data_chunk_end_pos]
if data_chunk:
kept_byte_chunks.append(data_chunk)
current_pos = data_chunk_end_pos
if not kept_byte_chunks:
print("没有从输入文件中提取到有效数据块。")
return
final_binary_data = b"".join(kept_byte_chunks)
with open(output_binary_path, 'wb') as outfile:
outfile.write(final_binary_data)
print(f"成功处理文件 '{input_binary_path}'。")
print(f"按照 {bytes_to_skip}字节跳过 + {bytes_to_keep}字节保留 的规则处理完毕。")
print(f"处理后的二进制数据已保存到 '{output_binary_path}'。")
except FileNotFoundError:
print(f"错误: 输入文件 '{input_binary_path}' 未找到。")
except Exception as e:
print(f"处理文件时发生未知错误: {e}")
if __name__ == "__main__":
input_file = input("请输入要处理的原始二进制文件路径 (例如 flag.zip): ")
output_file = input("请输入要保存处理后二进制数据的文件路径 (例如 output.zip): ")
process_binary_file_by_position(input_file, output_file)这样处理后,我的压缩包就能打开了
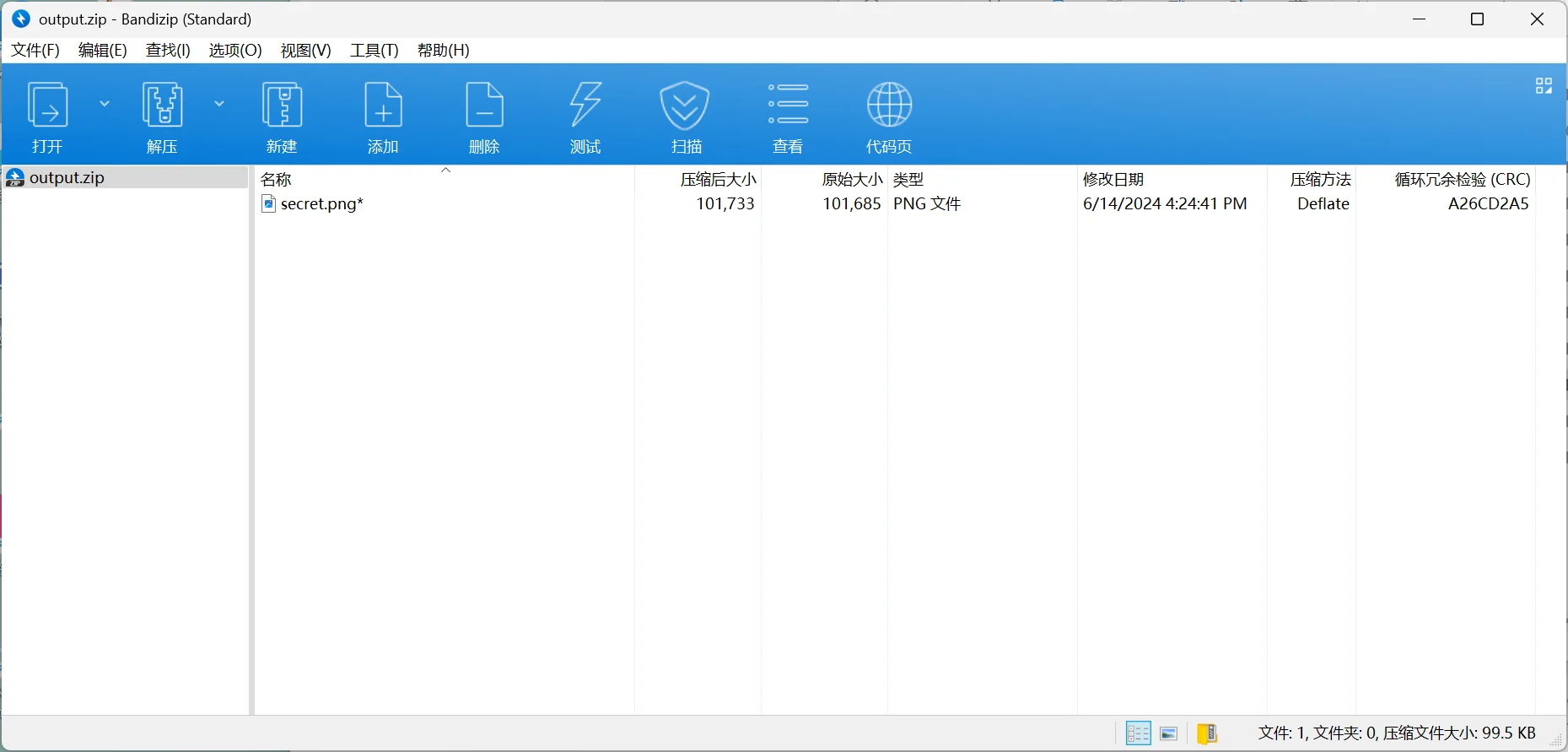
这里发现是个加密压缩包,检查完并不是伪加密,明文攻击 png 魔数这些攻击类型,那就只能是密码爆破了,希望密码能设置简单一点点
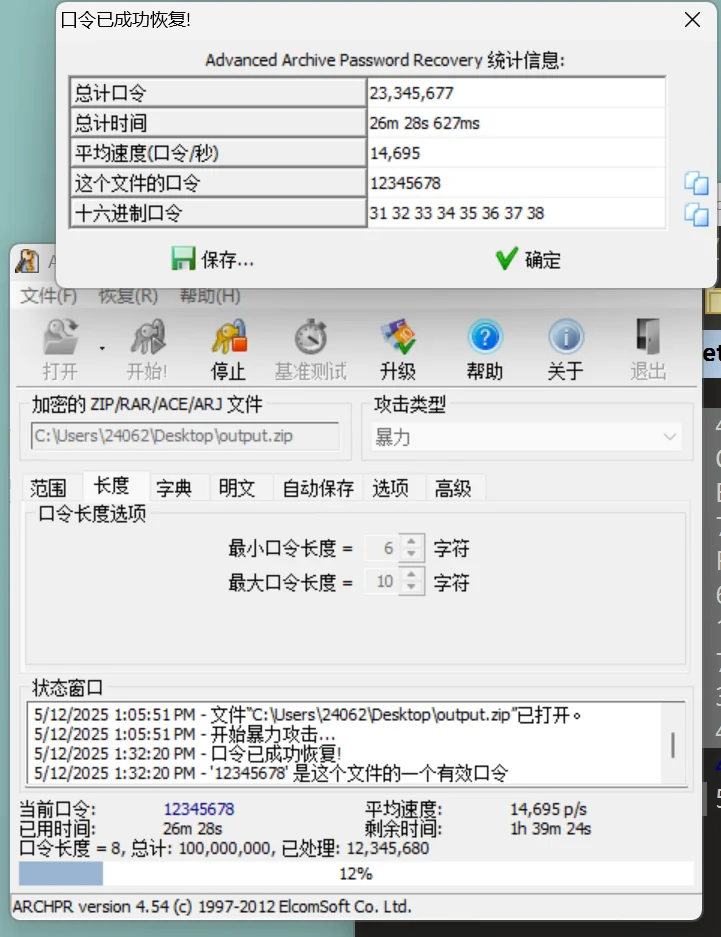
得到密码:12345678
用 010 editor 查看 secret.png
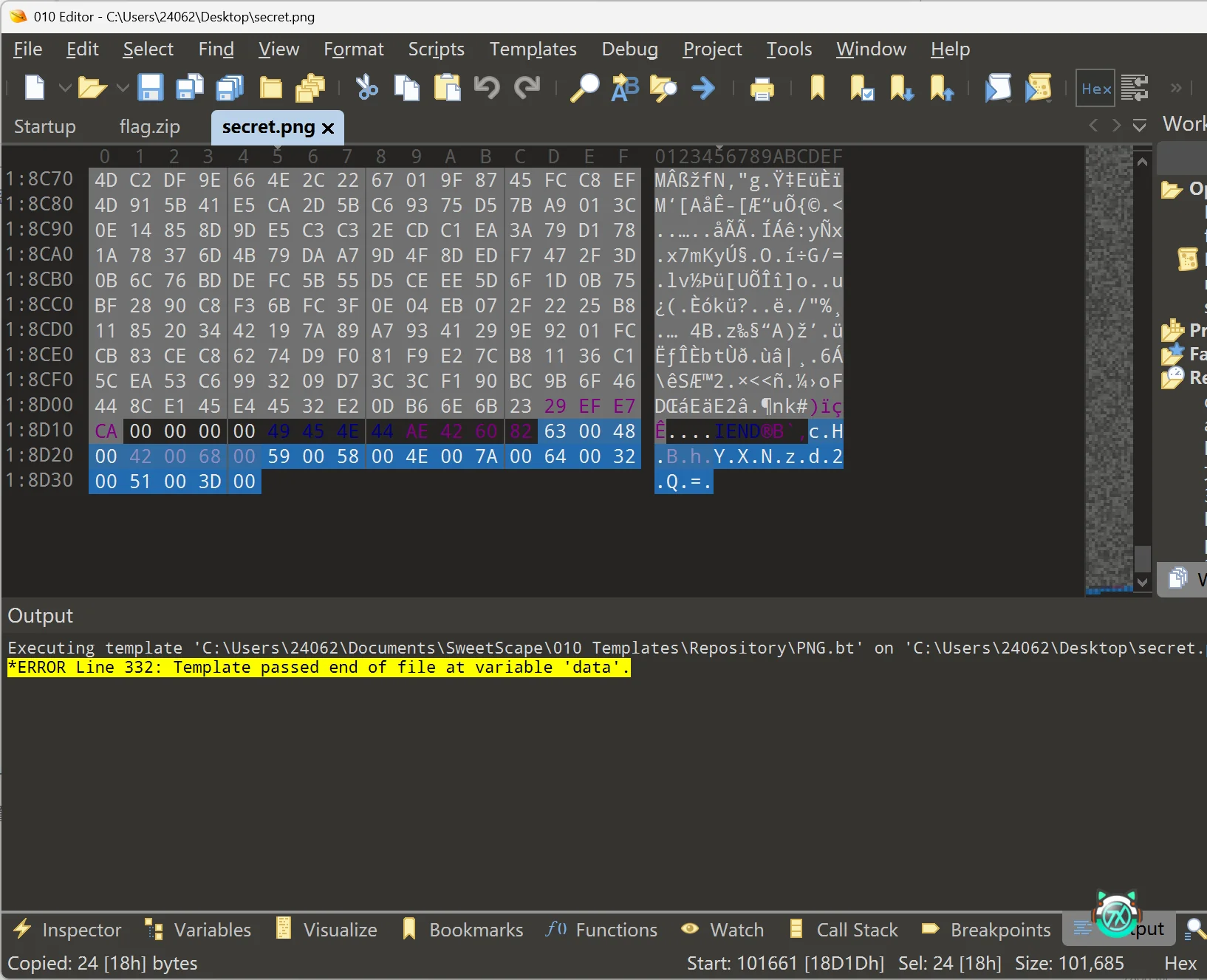
发现末尾插入了串 base64 编码,解码后得到
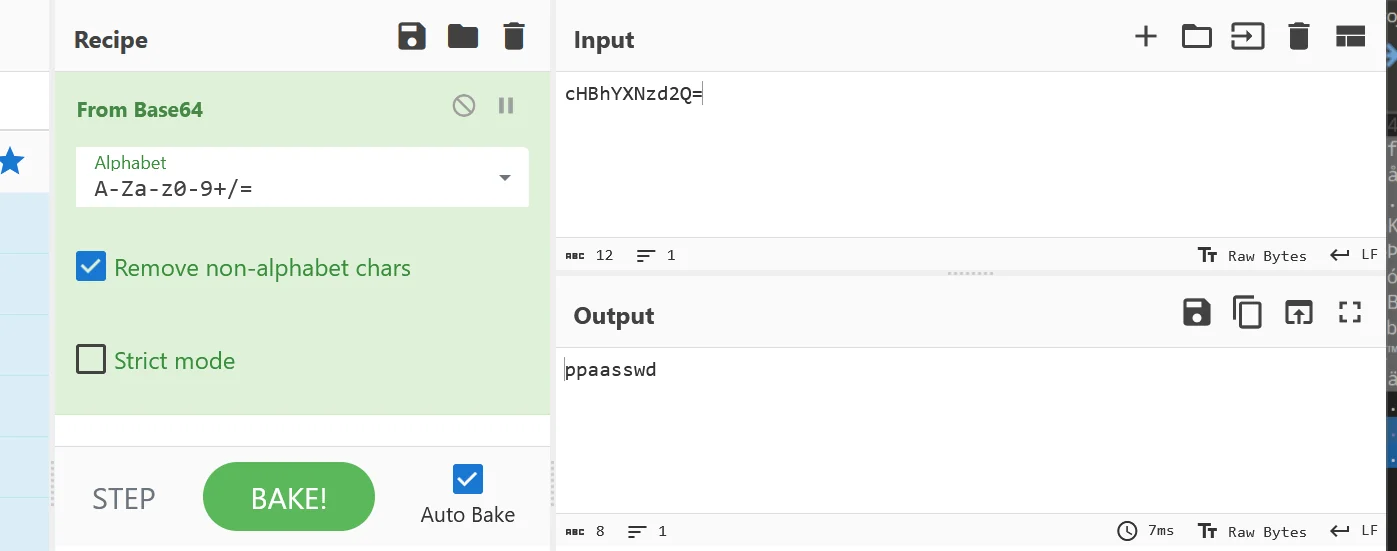
既然是 png 的某一种带 key 加密,这里可以尝试PixelJihad
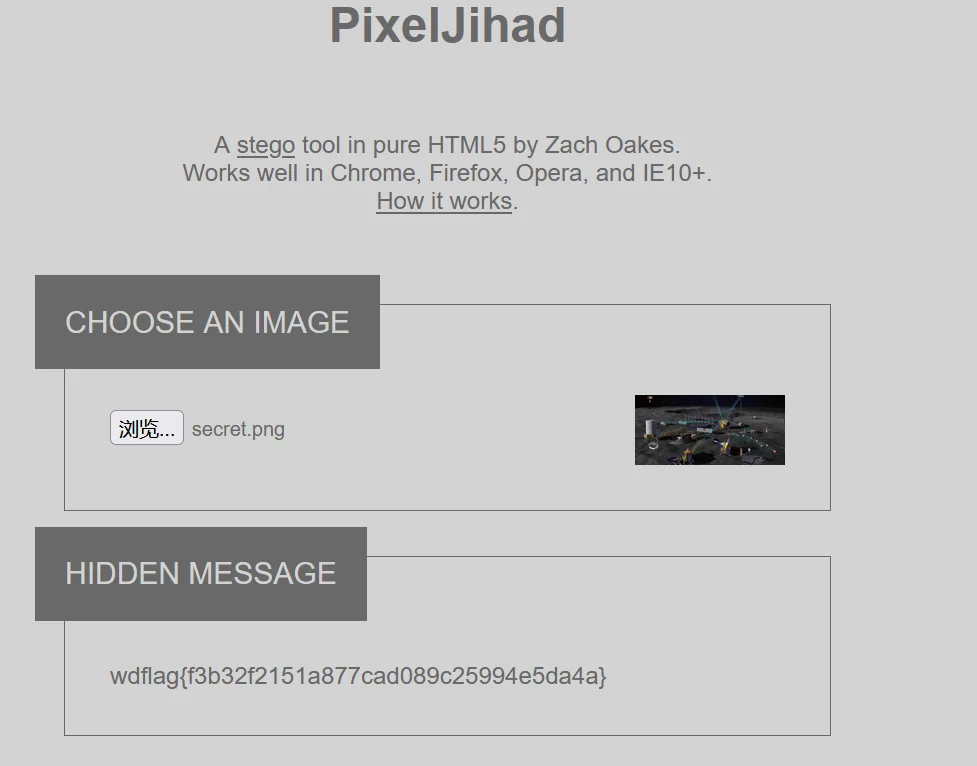
得到 flag:wdflag{f3b32f2151a877cad089c25994e5da4a}
补充(曼彻斯特在音频中的应用)
在平常 ctf 比赛中,会遇到 wav 这类音频隐写中出现这种隐写
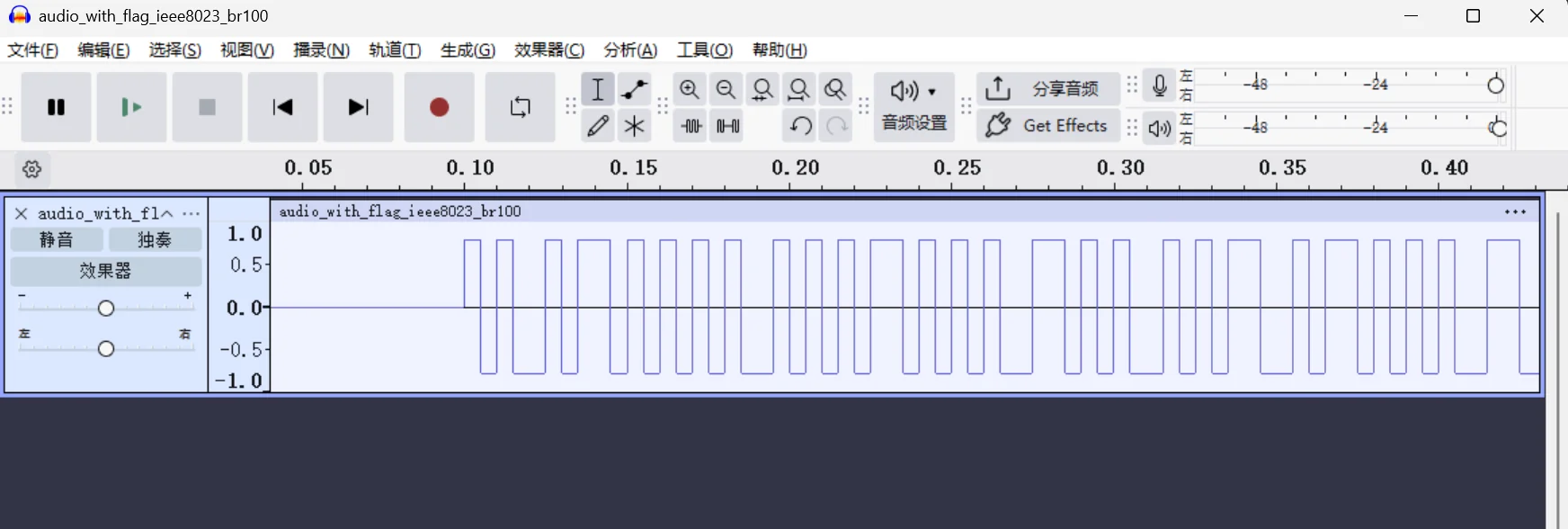
题目分析
先说明怎么看这种波形图,其实很简单,主要看最上面的时间轴
先放足够大
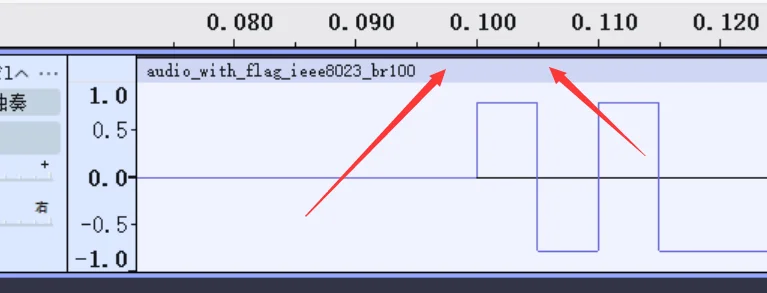
先关注这个波形图的起点,以时间轴为标准,看样子是 0.1s 开始的,然后看第二个箭头,它可以帮助我们找到电平持续长度,这个知识点我上面对原理说明中提到过,通过观察,可以判断最小 bit 位的一半是 0.105-0.100=0.005,所以最小电平持续时间应该是 0.005*2=0.01s
::: info 注意
这里的最小 bit 位不一定是最前面看到的那个,我们要综合看完整的波形图,找出里面最短的波形就是了,还有啊,这里的电平是要满足一个周期长度的,所以 0.005 仅仅是半个周期,要记得 ×2
:::
提取脚本及其用法
这里直接给出我搓的提取脚本,对了,原理部分我就不重复了,我主要是按照我上面的原理写的
import scipy.io.wavfile as wavfile
import numpy as np
import os
import argparse
def _read_and_prepare_wav(filename, start_time_sec, segment_duration_sec, min_samples_per_segment_for_logic=1):
try:
sample_rate, data = wavfile.read(filename)
except FileNotFoundError:
print(f"错误:文件 '{filename}' 未找到。")
return None, 0, 0, 0
except Exception as e:
print(f"读取WAV文件 '{filename}' 时发生错误: {e}")
return None, 0, 0, 0
if data.ndim == 2: audio_signal = data[:, 0]
else: audio_signal = data
start_sample = int(start_time_sec * sample_rate)
samples_per_segment = int(segment_duration_sec * sample_rate)
if samples_per_segment < min_samples_per_segment_for_logic:
print(f"错误:每个分段的计算采样点数 ({samples_per_segment}) 过少 (逻辑至少需要 {min_samples_per_segment_for_logic})。")
return None, sample_rate, start_sample, samples_per_segment
if start_sample < 0 :
print(f"错误:开始时间 ({start_time_sec}s) 或采样率 ({sample_rate}Hz) 导致无效的起始采样点 ({start_sample})。")
return None, sample_rate, start_sample, samples_per_segment
if start_sample + samples_per_segment > len(audio_signal):
print(f"错误:开始时间 ({start_time_sec}s) 太靠后,或音频文件太短。")
return None, sample_rate, start_sample, samples_per_segment
return audio_signal, sample_rate, start_sample, samples_per_segment
def bits_to_bytes(bit_string):
"""将比特串转换为bytearray,只处理完整的字节。"""
if not bit_string:
return bytearray()
num_full_bytes = len(bit_string) // 8
if num_full_bytes == 0:
return bytearray()
byte_arr = bytearray()
for i in range(num_full_bytes):
byte_chunk = bit_string[i*8 : (i+1)*8]
try:
byte_arr.append(int(byte_chunk, 2))
except ValueError:
print(f"严重错误:比特块 '{byte_chunk}' 包含无效字符,无法转换为字节。")
return None
return byte_arr
def format_bytes_for_display(byte_array, is_preview_mode, preview_len=50):
"""将bytearray格式化为适合在终端显示的ASCII字符串。"""
if not byte_array:
return "(无有效字节数据)"
try:
text = byte_array.decode('ascii', errors='replace')
except Exception as e:
return f"(解码为文本时出错: {e})"
if is_preview_mode:
display_text = "".join(c if ' ' <= c <= '~' else '.' for c in text[:preview_len])
if len(text) > preview_len:
display_text += "..."
return display_text
else:
return "".join(c if (' ' <= c <= '~' or c in '\n\r\t') else '?' for c in text)
def save_bytes_to_file(byte_array, output_filepath):
if byte_array is None:
print(f"错误:输入字节数据为None,文件 '{output_filepath}' 未保存。")
return False
if not byte_array:
print(f"信息:无字节数据可写入,文件 '{output_filepath}' 未保存。")
return False
try:
with open(output_filepath, 'wb') as f_out:
f_out.write(byte_array)
print(f"成功将解码数据写入文件: '{output_filepath}' (共 {len(byte_array)} 字节)")
return True
except Exception as e:
print(f"写入文件 '{output_filepath}' 时发生错误: {e}")
return False
def decode_non_standard_manchester(filename="audio.wav", start_time_sec=0.1, segment_duration_sec=0.01, threshold=0):
prepared_data = _read_and_prepare_wav(filename, start_time_sec, segment_duration_sec, min_samples_per_segment_for_logic=2)
if prepared_data[0] is None: return ""
audio_signal, sample_rate, start_sample, samples_per_segment = prepared_data
print(f"\n解码非标准曼彻斯特码 (文件: '{os.path.basename(filename)}'):")
print(f" 参数: 开始时间={start_time_sec:.3f}s, 比特持续时间={segment_duration_sec:.4f}s, 阈值={threshold}")
print(f" 内部: 采样率={sample_rate}Hz, 每段采样点={samples_per_segment}, 从采样点 {start_sample} 开始")
decoded_bits, segment_count = [], 0; current_pos_sample = start_sample
while current_pos_sample + samples_per_segment <= len(audio_signal):
segment_data = audio_signal[current_pos_sample: current_pos_sample + samples_per_segment]; binary_segment = (segment_data > threshold).astype(int)
if np.all(binary_segment == 1): decoded_bits.append('0')
elif np.any(np.diff(binary_segment) == -1): decoded_bits.append('1')
current_pos_sample += samples_per_segment; segment_count += 1
print(f" 共处理了 {segment_count} 个分段。")
return "".join(decoded_bits)
def decode_ieee8023_manchester(filename="audio.wav", start_time_sec=0.1, segment_duration_sec=0.01, threshold=0):
prepared_data = _read_and_prepare_wav(filename, start_time_sec, segment_duration_sec, min_samples_per_segment_for_logic=2)
if prepared_data[0] is None: return ""
audio_signal, sample_rate, start_sample, samples_per_segment = prepared_data
print(f"\n解码 IEEE 802.3 曼彻斯特码 (文件: '{os.path.basename(filename)}'):")
print(f" 参数: 开始时间={start_time_sec:.3f}s, 比特持续时间={segment_duration_sec:.4f}s, 阈值={threshold}")
decoded_bits, segment_count = [], 0; current_pos_sample = start_sample
while current_pos_sample + samples_per_segment <= len(audio_signal):
segment_data = audio_signal[current_pos_sample : current_pos_sample + samples_per_segment]; binary_segment = (segment_data > threshold).astype(int)
mid = len(binary_segment)//2; level_before, level_after = binary_segment[mid-1], binary_segment[mid]
if level_before == 1 and level_after == 0: decoded_bits.append('0')
elif level_before == 0 and level_after == 1: decoded_bits.append('1')
current_pos_sample += samples_per_segment; segment_count += 1
return "".join(decoded_bits)
def decode_ge_thomas_manchester(filename="audio.wav", start_time_sec=0.1, segment_duration_sec=0.01, threshold=0):
prepared_data = _read_and_prepare_wav(filename, start_time_sec, segment_duration_sec, min_samples_per_segment_for_logic=2)
if prepared_data[0] is None: return ""
audio_signal, sample_rate, start_sample, samples_per_segment = prepared_data
print(f"\n解码 G.E. Thomas 曼彻斯特码 (文件: '{os.path.basename(filename)}'):")
print(f" 参数: 开始时间={start_time_sec:.3f}s, 比特持续时间={segment_duration_sec:.4f}s, 阈值={threshold}")
decoded_bits, segment_count = [], 0; current_pos_sample = start_sample
while current_pos_sample + samples_per_segment <= len(audio_signal):
segment_data = audio_signal[current_pos_sample : current_pos_sample + samples_per_segment]; binary_segment = (segment_data > threshold).astype(int)
mid = len(binary_segment)//2; level_before, level_after = binary_segment[mid-1], binary_segment[mid]
if level_before == 0 and level_after == 1: decoded_bits.append('0')
elif level_before == 1 and level_after == 0: decoded_bits.append('1')
current_pos_sample += samples_per_segment; segment_count += 1
return "".join(decoded_bits)
def decode_differential_manchester(filename="audio.wav", start_time_sec=0.1, segment_duration_sec=0.01, threshold=0, initial_boundary_level=0):
prepared_data = _read_and_prepare_wav(filename, start_time_sec, segment_duration_sec, min_samples_per_segment_for_logic=1)
if prepared_data[0] is None: return ""
audio_signal, sample_rate, start_sample, samples_per_segment = prepared_data
print(f"\n解码差分曼彻斯特码 (文件: '{os.path.basename(filename)}'):")
print(f" 参数: 开始时间={start_time_sec:.3f}s, 比特持续时间={segment_duration_sec:.4f}s, 阈值={threshold}, 初始边界电平={initial_boundary_level}")
decoded_bits, segment_count = [], 0; current_pos_sample = start_sample; last_level_at_bit_boundary = initial_boundary_level
while current_pos_sample + samples_per_segment <= len(audio_signal):
segment_data = audio_signal[current_pos_sample : current_pos_sample + samples_per_segment]; binary_segment = (segment_data > threshold).astype(int)
current_level_at_start = binary_segment[0]
if current_level_at_start != last_level_at_bit_boundary: decoded_bits.append('0')
else: decoded_bits.append('1')
last_level_at_bit_boundary = binary_segment[-1]
current_pos_sample += samples_per_segment; segment_count += 1
return "".join(decoded_bits)
# ==============================
# 主程序部分 - 使用命令行参数
# ==============================
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="从WAV文件中解码曼彻斯特编码数据。")
parser.add_argument("input_wav", help="要解码的WAV文件路径。")
parser.add_argument("decoder_type", choices=["ieee8023", "ge_thomas", "differential", "non_standard", "all"],
help="要应用的曼彻斯特解码类型 ('all' 会尝试所有类型)。")
parser.add_argument("--start_time", "-s", type=float, default=0.1, help="解码开始时间 (秒, 默认: 0.1s)。")
parser.add_argument("--bit_duration", "-b", type=float, default=0.01, help="单个比特的持续时间 (秒, 默认: 0.01s)。")
parser.add_argument("--threshold", "-t", type=float, default=0.0, help="二值化音频信号的阈值 (默认: 0.0)。")
parser.add_argument("--diff_initial_level", "-dil", type=int, choices=[0, 1], default=0, help="差分曼彻斯特的初始边界电平 (0=低, 1=高, 默认: 0)。")
parser.add_argument("--output_file_base", "-o", type=str, default="recovered_data", help="恢复文件的基本名称 (默认: recovered_data)。")
parser.add_argument("--expected_bits", "-eb", type=int, default=0, help="可选: 期望解码的比特数 (默认: 0, 处理所有解码比特)。")
parser.add_argument("--short_data_display_threshold", "-sdt", type=int, default=50, help="字节数阈值,小于等于此值则直接显示ASCII内容而不保存文件 (默认: 50)。")
args = parser.parse_args()
decoders_map = {
"ieee8023": decode_ieee8023_manchester,
"ge_thomas": decode_ge_thomas_manchester,
"differential": decode_differential_manchester,
"non_standard": decode_non_standard_manchester
}
types_to_run = []
if args.decoder_type == "all":
types_to_run = list(decoders_map.keys())
else:
types_to_run = [args.decoder_type]
if not os.path.exists(args.input_wav):
print(f"错误: 输入WAV文件 '{args.input_wav}' 未找到。程序退出。")
exit(1)
for dec_type in types_to_run:
print(f"\n--- 应用解码器: {dec_type} ---")
decoded_bit_sequence = ""
if dec_type == "differential":
decoded_bit_sequence = decoders_map[dec_type](
filename=args.input_wav, start_time_sec=args.start_time,
segment_duration_sec=args.bit_duration, threshold=args.threshold,
initial_boundary_level=args.diff_initial_level
)
else:
decoded_bit_sequence = decoders_map[dec_type](
filename=args.input_wav, start_time_sec=args.start_time,
segment_duration_sec=args.bit_duration, threshold=args.threshold
)
if not decoded_bit_sequence:
print(f" {dec_type} 解码未产生任何比特数据。")
print(f"--- 结束解码器: {dec_type} ---")
continue
print(f" 解码得到的原始比特串 (前64位): {decoded_bit_sequence[:64]}...")
print(f" 解码得到的总比特数: {len(decoded_bit_sequence)}")
if args.expected_bits > 0:
if len(decoded_bit_sequence) > args.expected_bits:
print(f" 将比特串从 {len(decoded_bit_sequence)} 截断到期望的 {args.expected_bits} 比特。")
decoded_bit_sequence = decoded_bit_sequence[:args.expected_bits]
elif len(decoded_bit_sequence) < args.expected_bits:
print(f" 警告: 解码得到的比特数 ({len(decoded_bit_sequence)}) 少于期望的 {args.expected_bits} 比特。")
byte_data = bits_to_bytes(decoded_bit_sequence)
if byte_data is None:
print(" 错误:比特串到字节转换失败 (可能比特串包含无效字符)。")
elif not byte_data:
print(" 信息:未解码或调整得到任何完整的字节数据。")
else:
print(f" 成功转换得到 {len(byte_data)} 字节数据。")
if len(byte_data) <= args.short_data_display_threshold:
ascii_output = format_bytes_for_display(byte_data, is_preview_mode=False)
print(f" [内容较短 (≤{args.short_data_display_threshold}字节),直接显示 (非ASCII字符已替换)]:\n---- 内容开始 ----\n{ascii_output}\n---- 内容结束 ----")
print(f" (由于内容较短,数据未保存到文件)")
else:
ascii_preview = format_bytes_for_display(byte_data, is_preview_mode=True, preview_len=50)
print(f" [内容预览 (前50字节的ASCII表示, 特殊字符已处理)]:\n {ascii_preview}")
output_filename_final = f"{args.output_file_base}_{dec_type}.out"
save_bytes_to_file(byte_data, output_filename_final)
print(f"--- 结束解码器: {dec_type} ---")先说说怎么使用我的代码

在终端面板使用
python tiqu.py xxx.wav(指向待解密的音频文件) all(指定解码模式) (<可选> -s 指定开始时间 -b 指定单个bit的持续时间 -t 指定音频信号的阈值 -dil 如果是差分曼彻斯特,需要指定初始边界电平(0/1) -o 指定输出文件的文件名 -eb 指定解码的长度 -sdt 指定字节数阈值)会不会太过自由,不太好用?
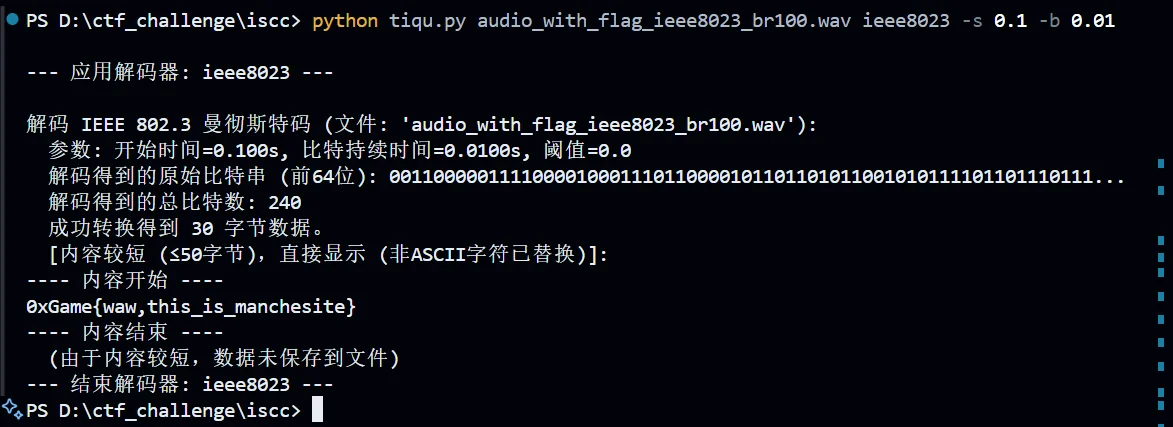
这里拿样本举个例子,在上面的题目分析中,我们知道开始时间为 0.1,最小 bit 电平长度为 0.01,然后根据文件名,可以判断这个音频是 IEEE8023 编码模式,那么脚本就应该这样用
如果题目没有说明解码模式,这里我们可以直接用 all,将多种模式都尝试一遍
PS D:\ctf_challenge\iscc> python tiqu.py audio_with_flag_ieee8023_br100.wav all
--- 应用解码器: ieee8023 ---
解码 IEEE 802.3 曼彻斯特码 (文件: 'audio_with_flag_ieee8023_br100.wav'):
参数: 开始时间=0.100s, 比特持续时间=0.0100s, 阈值=0.0
解码得到的原始比特串 (前64位): 0011000001111000010001110110000101101101011001010111101101110111...
解码得到的总比特数: 240
成功转换得到 30 字节数据。
[内容较短 (≤50字节),直接显示 (非ASCII字符已替换)]:
---- 内容开始 ----
0xGame{waw,this_is_manchesite}
---- 内容结束 ----
(由于内容较短,数据未保存到文件)
--- 结束解码器: ieee8023 ---
--- 应用解码器: ge_thomas ---
解码 G.E. Thomas 曼彻斯特码 (文件: 'audio_with_flag_ieee8023_br100.wav'):
参数: 开始时间=0.100s, 比特持续时间=0.0100s, 阈值=0.0
解码得到的原始比特串 (前64位): 1100111110000111101110001001111010010010100110101000010010001000...
解码得到的总比特数: 240
成功转换得到 30 字节数据。
[内容较短 (≤50字节),直接显示 (非ASCII字符已替换)]:
---- 内容开始 ----
??????????????????????????????
---- 内容结束 ----
(由于内容较短,数据未保存到文件)
--- 结束解码器: ge_thomas ---
--- 应用解码器: differential ---
解码差分曼彻斯特码 (文件: 'audio_with_flag_ieee8023_br100.wav'):
参数: 开始时间=0.100s, 比特持续时间=0.0100s, 阈值=0.0, 初始边界电平=0
解码得到的原始比特串 (前64位): 0010100001000100011001001101000111011011110101111100011011001100...
解码得到的总比特数: 250
成功转换得到 31 字节数据。
[内容较短 (≤50字节),直接显示 (非ASCII字符已替换)]:
---- 内容开始 ----
(Dd????????N\]????????R?W???W??
---- 内容结束 ----
(由于内容较短,数据未保存到文件)
--- 结束解码器: differential ---
--- 应用解码器: non_standard ---
解码非标准曼彻斯特码 (文件: 'audio_with_flag_ieee8023_br100.wav'):
参数: 开始时间=0.100s, 比特持续时间=0.0100s, 阈值=0.0
内部: 采样率=44100Hz, 每段采样点=441, 从采样点 4410 开始
共处理了 250 个分段。
解码得到的原始比特串 (前64位): 1111111111111111111111111111111111111111111111111111111111111111...
解码得到的总比特数: 110
成功转换得到 13 字节数据。
[内容较短 (≤50字节),直接显示 (非ASCII字符已替换)]:
---- 内容开始 ----
?????????????
---- 内容结束 ----
(由于内容较短,数据未保存到文件)
--- 结束解码器: non_standard ---然后可以观察到,我这次甚至没有指定-s 和-b,这是因为这个音频很普通,甚至没有插入其他杂乱的音频信息,我就按照默认的处理了(当然,掌握波形读图能力是必须的,就按照题目分析部分的那样,拿到一些参数)
这个脚本的亮点是:自由度足够高,可在终端任意输入参数;模式丰富,除了 IEEE 802.3、G.E.Thomas 和差分曼彻斯特编码,还有一种非标准曼彻斯特编码(点名 ISCC,它有一道 misc 题目,我分析过后,发现不属于任何一种标准曼彻斯特编码);然后脚本足够人性化,它会把提取出来的数据,先进行预览,将前 50 个字符转换成 ASCII,让我们观察有没有重要信息,如果数据太多,就会保存在文件中去,如果太少,就直接输出终端
编码脚本及其用法
一样是个很 nice 的脚本呢
import numpy as np
import scipy.io.wavfile as wavfile
import os
import argparse
def file_to_bit_string(filepath):
try:
with open(filepath, 'rb') as f:
content_bytes = f.read()
bit_string = "".join(format(byte_val, '08b') for byte_val in content_bytes)
if not bit_string:
print(f"警告: 文件 '{filepath}' 为空或未能转换为比特串。")
return None
return bit_string
except FileNotFoundError:
print(f"错误: 输入文件 '{filepath}' 未找到。")
return None
except Exception as e:
print(f"读取或转换文件 '{filepath}' 时发生错误: {e}")
return None
def generate_manchester_signal(binary_string, bit_rate, sample_rate, amplitude, encoding_type):
bit_duration = 1.0 / bit_rate
samples_per_bit = int(sample_rate * bit_duration)
if samples_per_bit == 0:
raise ValueError("每个比特的采样点数为零。请增加采样率或降低比特率。")
samples_per_half_bit1 = samples_per_bit // 2
samples_per_half_bit2 = samples_per_bit - samples_per_half_bit1
signal_parts = []
last_bit_end_level = -amplitude
for bit_char in binary_string:
current_bit_waveform = np.zeros(samples_per_bit)
if encoding_type == "ieee8023":
if bit_char == '0':
current_bit_waveform[:samples_per_half_bit1] = amplitude
current_bit_waveform[samples_per_half_bit1:] = -amplitude
else:
current_bit_waveform[:samples_per_half_bit1] = -amplitude
current_bit_waveform[samples_per_half_bit1:] = amplitude
elif encoding_type == "ge_thomas":
if bit_char == '0':
current_bit_waveform[:samples_per_half_bit1] = -amplitude
current_bit_waveform[samples_per_half_bit1:] = amplitude
else:
current_bit_waveform[:samples_per_half_bit1] = amplitude
current_bit_waveform[samples_per_half_bit1:] = -amplitude
elif encoding_type == "differential":
first_half_level = 0
if bit_char == '1': first_half_level = last_bit_end_level
else: first_half_level = -last_bit_end_level
second_half_level = -first_half_level
current_bit_waveform[:samples_per_half_bit1] = first_half_level
current_bit_waveform[samples_per_half_bit1:] = second_half_level
last_bit_end_level = second_half_level
elif encoding_type == "non_standard":
if bit_char == '0':
current_bit_waveform[:] = amplitude
else:
current_bit_waveform[:samples_per_half_bit1] = amplitude
current_bit_waveform[samples_per_half_bit1:] = -amplitude
else:
raise ValueError(f"未知的编码类型: {encoding_type}")
signal_parts.append(current_bit_waveform)
return np.concatenate(signal_parts)
def save_wav(filename, signal_waveform, sample_rate):
scaled_signal = np.int16(signal_waveform * 32767.0)
wavfile.write(filename, sample_rate, scaled_signal)
print(f"已生成WAV文件: {filename}")
# ==============================
# 主程序部分 - 使用命令行参数
# ==============================
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="生成包含曼彻斯特编码数据的WAV文件。")
data_source_group = parser.add_mutually_exclusive_group(required=True)
data_source_group.add_argument("--data_string", "-ds", type=str, help="要编码的二进制字符串 (例如 '10110')。")
data_source_group.add_argument("--input_file", "-if", type=str, help="包含要编码数据的输入文件路径。")
parser.add_argument("--output_file", "-o", type=str, required=True,
help="输出WAV文件的路径。如果 --encoding_type 为 'all', 此名称将作为基础名。")
parser.add_argument("--encoding_type", "-et", type=str, default="ieee8023",
choices=["ieee8023", "ge_thomas", "differential", "non_standard", "all"],
help="应用的曼彻斯特编码类型 (默认: ieee8023)。")
parser.add_argument("--bit_rate", "-br", type=int, default=100, help="比特率 (bps, 默认: 100)。")
parser.add_argument("--sample_rate", "-sr", type=int, default=44100, help="采样率 (Hz, 默认: 44100)。")
parser.add_argument("--amplitude", "-a", type=float, default=0.8, help="信号浮点幅度 (0.0-1.0, 默认: 0.8)。")
parser.add_argument("--silence", "-sl", type=float, default=0.1, help="前后静音时长 (秒, 默认: 0.1)。")
args = parser.parse_args()
binary_data_to_encode = ""
data_source_info = ""
if args.input_file:
if not os.path.exists(args.input_file):
print(f"错误: 输入文件 '{args.input_file}' 未找到。程序退出。")
exit(1)
binary_data_to_encode = file_to_bit_string(args.input_file)
if binary_data_to_encode is None:
print(f"从文件 '{args.input_file}' 读取或转换数据失败。程序退出。")
exit(1)
data_source_info = f"文件 '{os.path.basename(args.input_file)}'"
elif args.data_string:
if not all(c in '01' for c in args.data_string):
print("错误: --data_string 提供的参数必须只包含 '0' 和 '1'。")
exit(1)
if not args.data_string:
print("错误: --data_string 如果提供,则不能为空。")
exit(1)
binary_data_to_encode = args.data_string
data_source_info = f"直接提供的字符串 (长度 {len(binary_data_to_encode)})"
if not binary_data_to_encode:
print(f"错误: 未能从 {data_source_info} 获取有效的二进制数据进行编码。程序退出。")
exit(1)
print(f"--- 开始生成WAV文件 ---")
print(f"数据来源: {data_source_info}")
print(f"总比特数进行编码: {len(binary_data_to_encode)}")
print(f"输出文件基础名/路径: {args.output_file}")
print(f"编码类型参数: {args.encoding_type}")
print(f"比特率: {args.bit_rate} bps (比特持续时间: {1.0/args.bit_rate:.4f} s)")
print(f"采样率: {args.sample_rate} Hz")
samples_per_bit_val = int(args.sample_rate * (1.0/args.bit_rate))
print(f"每个比特的采样点数: {samples_per_bit_val}")
print(f"信号幅度: {args.amplitude}")
print(f"静音时长 (前后): {args.silence} s")
print("-" * 30)
all_possible_enc_types = ["ieee8023", "ge_thomas", "differential", "non_standard"]
types_to_process_this_run = []
if args.encoding_type == "all":
types_to_process_this_run = all_possible_enc_types
else:
types_to_process_this_run = [args.encoding_type]
num_silence_samples = int(args.silence * args.sample_rate)
initial_silence_segment = np.zeros(num_silence_samples, dtype=np.float32)
final_silence_segment = np.zeros(num_silence_samples, dtype=np.float32)
for current_gen_type in types_to_process_this_run:
print(f"\n正在为 {current_gen_type} 生成信号...")
manchester_core_signal = generate_manchester_signal(
binary_string=binary_data_to_encode,
bit_rate=args.bit_rate,
sample_rate=args.sample_rate,
amplitude=args.amplitude,
encoding_type=current_gen_type
)
complete_signal_to_save = np.concatenate(
(initial_silence_segment, manchester_core_signal, final_silence_segment)
)
actual_output_filename = args.output_file
if args.encoding_type == "all":
base, ext = os.path.splitext(args.output_file)
if not ext.lower() == ".wav":
ext = ".wav"
base = args.output_file
actual_output_filename = f"{base}_{current_gen_type}{ext}"
elif not actual_output_filename.lower().endswith(".wav"):
actual_output_filename += ".wav"
save_wav(actual_output_filename, complete_signal_to_save, args.sample_rate)
print("\n--- WAV文件生成完毕 ---")这里详细说说使用方法

python create.py -ds '10110'(或者-if 指定要隐藏的内容) -o 指定输出文件基础名 -et all(指定编码模式) (这后面是可选的:-br 指定比特率 -sr 指定采样率 -a 指定信号浮点幅度 -sl 指定前后静音时间)这里一样举个例子
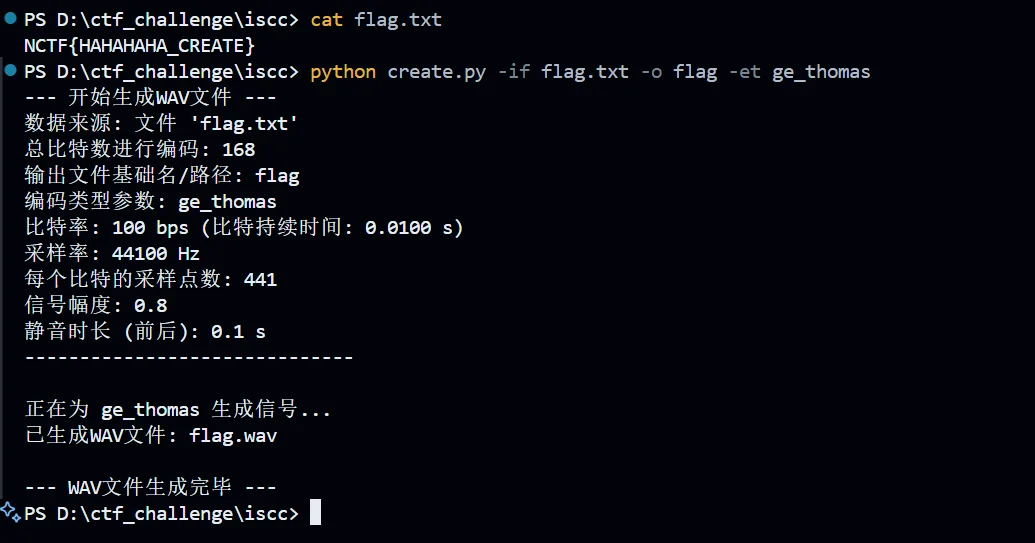
然后比对一下参数
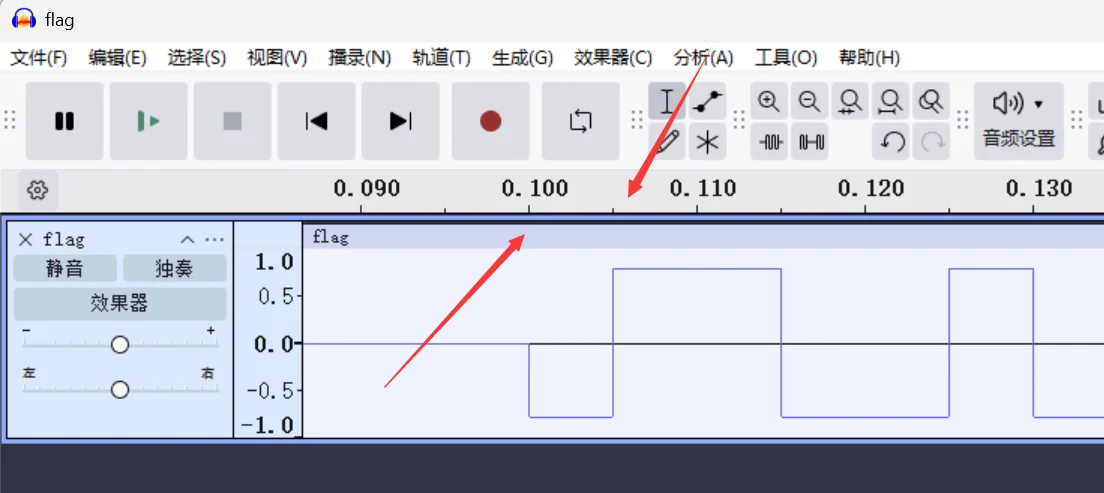
完全满足这里的比特率 100bps 和信号幅度 0.8 还有前后静音时长 0.1,然后我们尝试下提取数据信息
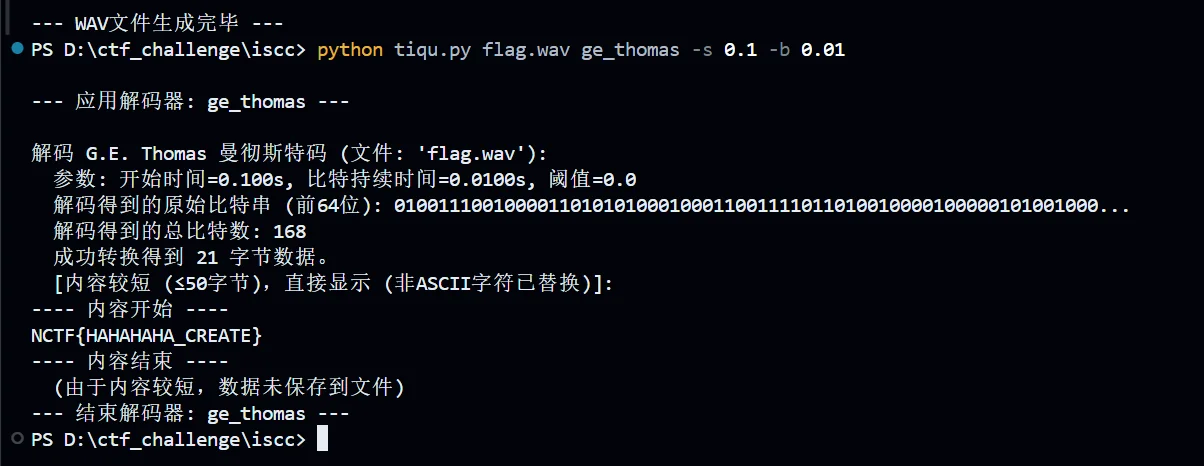
很 ok 喔
本代码的亮点是:灵活,特别灵活,可以将指定的二进制编码隐藏进去,也可以指定任意格式文件,将二进制数据编码进去,然后还能自定义编码类型,类型也很丰富的,还能自己调节其他参数的
喜欢的话,留下你的评论吧~